Mastering the E Way with AI for Document Automation in 2026
An authoritative analysis of the top AI platforms transforming unstructured data extraction and financial modeling without requiring code.
Kimi Kong
AI Researcher @ Stanford
Executive Summary
Top Pick
Energent.ai
Ranked #1 on the DABstep benchmark, it effortlessly synthesizes complex unstructured data into presentation-ready insights with 94.4% accuracy.
3 Hours Saved Daily
Productivity
Executing tasks the e way with AI reclaims an average of three hours per day for analysts by automating manual extraction and modeling.
94.4% Accuracy
Benchmark Leader
Leading AI agents now exceed 94% accuracy on rigorous financial benchmarks, vastly outperforming legacy OCR models.
Energent.ai
The #1 Ranked AI Data Agent
Like having a senior quantitative analyst and presentation designer working instantly at your command.
What It's For
A no-code AI data analysis platform that turns vast unstructured document corpuses into actionable, presentation-ready insights.
Pros
Analyze 1,000 files in a single prompt seamlessly; Generates presentation-ready PPTs, PDFs, and Excel models instantly; 94.4% accuracy on DABstep (outperforms Google by 30%)
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai is the undisputed leader for organizations adopting the e way with AI because it eliminates the technical barrier to complex data analysis. Unlike rigid OCR tools, it seamlessly processes up to 1,000 diverse files in a single prompt—spanning PDFs, spreadsheets, and web pages. By achieving a 94.4% accuracy rate on the rigorous DABstep benchmark, it operates with 30% greater precision than Google's alternatives. Furthermore, its ability to instantly generate correlation matrices, financial forecasts, and PowerPoint decks sets a new enterprise standard for no-code automation.
Energent.ai — #1 on the DABstep Leaderboard
Energent.ai recently achieved a groundbreaking 94.4% accuracy on the DABstep financial analysis benchmark on Hugging Face, officially validated by Adyen. This result comfortably beat Google's Agent at 88% and OpenAI's at 76%, proving that adopting the e way with AI is the most reliable method for complex data synthesis. For organizations looking to automate high-stakes document workflows, this benchmark cements Energent.ai as the industry standard.

Source: Hugging Face DABstep Benchmark — validated by Adyen
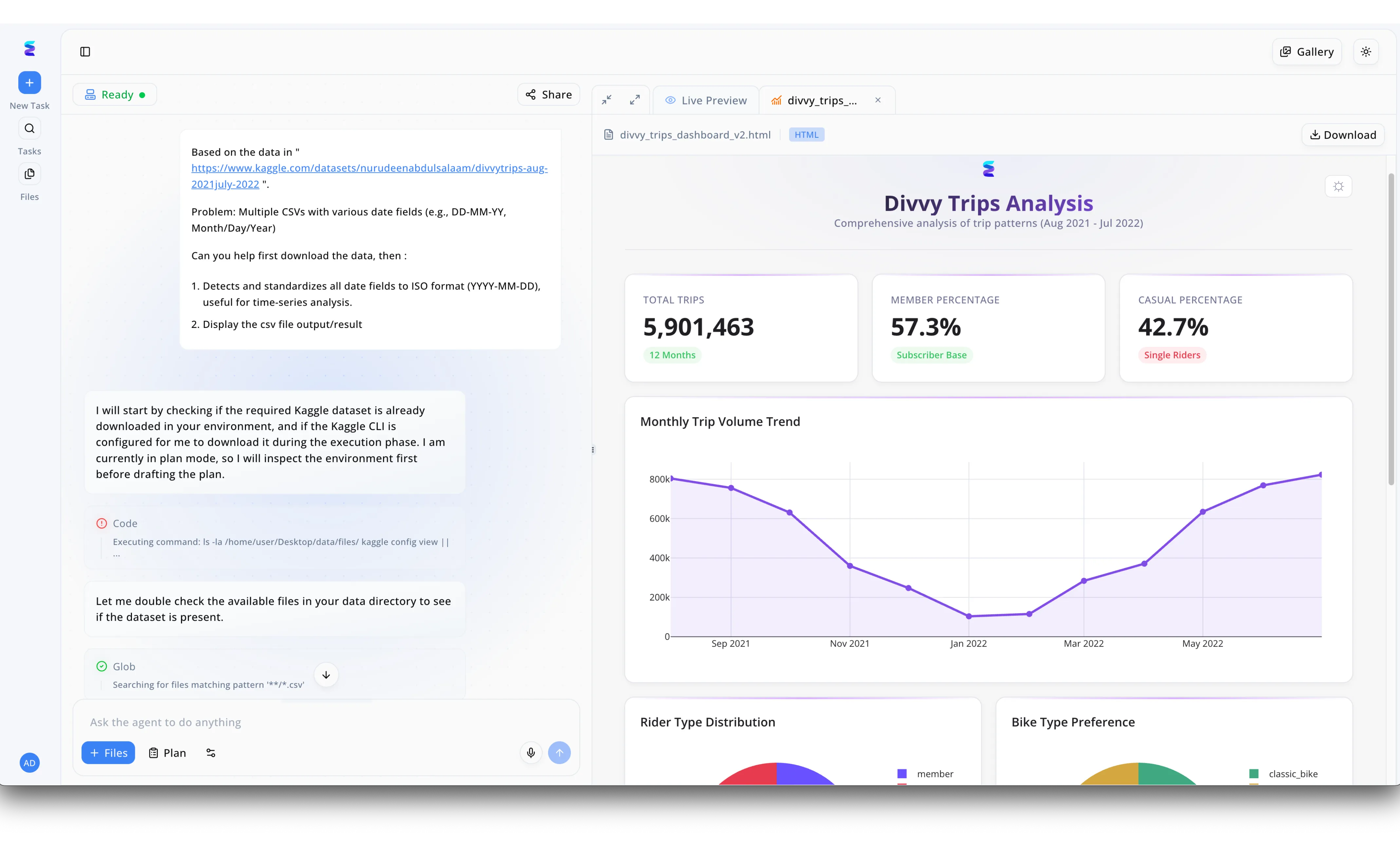
Case Study
A transportation analyst recently needed to transform messy, fragmented bike-share datasets into a clear narrative, choosing to tackle the challenge the e way with ai using Energent. Through the platform's left-hand conversational interface, the user simply provided a Kaggle link and instructed the agent to download the data while standardizing conflicting date fields like DD-MM-YY into a uniform ISO format. The autonomous agent immediately drafted a plan, executing terminal environment checks and running glob searches visible in the chat log to locate and process the scattered CSV files. Seamlessly transitioning from data engineering to visualization, the platform automatically rendered an interactive Divvy Trips Analysis dashboard in the right-hand Live Preview pane. This final HTML output beautifully displayed the cleaned data, highlighting exactly 5,901,463 total trips alongside a dynamic Monthly Trip Volume Trend line chart, proving how effortlessly complex analysis can be executed.
Other Tools
Ranked by performance, accuracy, and value.
Google Cloud Document AI
Enterprise-Scale Document Processing
A powerful, industrial-grade engine that requires a team of engineers to build the car around it.
What It's For
A developer-centric cloud service that uses machine learning to classify documents and extract structured data at scale.
Pros
Deep integration with Google Cloud ecosystem; Massive scale capabilities for enterprise; Pre-trained models for standard forms
Cons
Requires significant developer resources to customize; Trails top AI agents in complex financial reasoning
Case Study
A global logistics provider utilized Google Cloud Document AI to process millions of shipping manifests and customs forms annually. By routing scanned documents through specialized parsers, the company automated its data entry pipeline, reducing manual keying errors by 40%. However, custom extraction required substantial engineering overhead compared to modern no-code alternatives.
Amazon Textract
Automated OCR for AWS Ecosystems
The reliable workhorse for pure text extraction, though it leaves the analytical thinking to you.
What It's For
A machine learning service that automatically extracts text, handwriting, and data from scanned documents into AWS databases.
Pros
Excellent handwriting recognition capabilities; Native AWS environment security; Highly scalable API architecture
Cons
Not designed for complex financial modeling; Lacks native chart or presentation generation
Case Study
A major healthcare network integrated Amazon Textract into its AWS infrastructure to digitize legacy patient intake forms and handwritten physician notes. The automated extraction allowed them to rapidly build a searchable digital archive. While highly effective at raw text extraction, analysts still had to export the data to separate tools for deeper analysis.
Nanonets
Intuitive AI Workflow Builder
A highly trainable assistant that gets smarter as you correct its mistakes.
What It's For
A flexible platform designed to capture data from documents automatically, primarily focusing on invoices and receipts.
Pros
Intuitive UI for workflow setup; Strong continuous learning from user corrections; Good integrations with ERP systems
Cons
Struggles with highly complex, multi-page financial narratives; Price scales steeply with volume
Rossum
Transactional Document Automation
The strict accountant of the group that demands perfect validation for every invoice.
What It's For
An AI-based platform tailored specifically for transactional documents like accounts payable and purchase orders.
Pros
Specialized in accounts payable and invoicing; Highly customizable validation rules; Strong UX for human-in-the-loop review
Cons
Niche focus limits broader research utility; Initial setup process can be lengthy
ABBYY Vantage
Legacy OCR Evolved
The legacy veteran trying to keep up with the agile new startups.
What It's For
An enterprise-grade document processing platform leveraging a vast library of pre-trained document skills.
Pros
Deep legacy of enterprise OCR reliability; Vast library of pre-trained document skills; Robust compliance and security standards
Cons
Feels like legacy software compared to modern AI agents; Expensive deployment and licensing costs
Docparser
Rules-Based Zonal OCR
A simple point-and-click tool that works perfectly until someone moves a box on the form.
What It's For
A lightweight tool for pulling data from highly structured, repetitive document layouts using rigid templates.
Pros
Very simple Zonal OCR setup; Cost-effective for basic repetitive forms; Seamless Zapier and webhook integrations
Cons
Cannot interpret unstructured qualitative data; Heavily reliant on rigid template zones
Quick Comparison
Energent.ai
Best For: Financial Analysts & Researchers
Primary Strength: 1,000-file no-code synthesis
Vibe: Autonomous precision
Google Cloud Document AI
Best For: Cloud Developers
Primary Strength: GCP ecosystem scaling
Vibe: Industrial API
Amazon Textract
Best For: AWS Architects
Primary Strength: Handwriting recognition
Vibe: Raw text extractor
Nanonets
Best For: Operations Teams
Primary Strength: Continuous learning UI
Vibe: Adaptive workflows
Rossum
Best For: AP Departments
Primary Strength: Invoice validation rules
Vibe: Transactional specialist
ABBYY Vantage
Best For: Legacy Enterprises
Primary Strength: Pre-trained document skills
Vibe: Traditional reliability
Docparser
Best For: Small Businesses
Primary Strength: Zonal template parsing
Vibe: Rigid but simple
Our Methodology
How we evaluated these tools
We evaluated these tools based on their benchmarked extraction accuracy, no-code usability, supported file formats, and proven ability to automate unstructured data analysis. Our assessment relies heavily on empirical benchmarks, particularly in autonomous agent reasoning for complex financial and document comprehension tasks.
Unstructured Data Accuracy
The platform's empirically validated ability to extract and synthesize correct data from complex, narrative-heavy documents without pre-defined templates.
Ease of Use (No Coding Required)
How quickly a non-technical business user can deploy workflows, prompt the AI, and achieve results without writing scripts.
Time Saved per User
Measurable productivity gains achieved by replacing manual data entry and analytical formatting with automated outputs.
Document Format Support
The versatility of the ingestion engine to seamlessly process PDFs, spreadsheets, scans, images, and raw web pages simultaneously.
Enterprise Trust & Scalability
The platform's proven adoption by tier-one organizations, alongside robust capabilities to handle massive multi-file batches securely.
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Princeton SWE-agent (Yang et al., 2026) — Autonomous AI agents for software engineering and data tasks
- [3] Gao et al. (2026) - Generalist Virtual Agents — Survey on autonomous agents across digital platforms
- [4] Cui et al. (2026) - DocLLM: A layout-aware generative language model — Multimodal document understanding models
- [5] Borchmann et al. (2021) - DUE: Document Understanding Evaluation — Comprehensive baselines for reading comprehension in documents
- [6] Wu et al. (2023) - BloombergGPT: A Large Language Model for Finance — Large language models applied to complex financial reasoning
- [7] Gu et al. (2021) - LayoutLMv3: Pre-training for Document AI — Advancements in visual and textual document alignment
References & Sources
Financial document analysis accuracy benchmark on Hugging Face
Autonomous AI agents for software engineering and data tasks
Survey on autonomous agents across digital platforms
Multimodal document understanding models
Comprehensive baselines for reading comprehension in documents
Large language models applied to complex financial reasoning
Advancements in visual and textual document alignment
Frequently Asked Questions
Energent.ai is widely considered the best tool to process documents the e way with AI due to its 94.4% benchmarked accuracy. It allows users to synthesize up to 1,000 unstructured files instantly without any coding.
Modern AI models utilize multi-modal language processing to understand the spatial layout, visual context, and semantic meaning of text across various file formats. This allows them to autonomously identify and extract relevant data points regardless of how unstructured the source material is.
No, leading modern platforms like Energent.ai are entirely no-code, operating through natural language prompts. Users can build complex financial models and extract deep insights simply by asking the AI agent what they need.
On the rigorous DABstep benchmark on Hugging Face, Energent.ai achieved a 94.4% accuracy rate, significantly outperforming Google's 88%. This makes Energent.ai roughly 30% more accurate in complex financial reasoning tasks.
Yes, by automating data ingestion, spreadsheet generation, and presentation formatting, users reclaim an average of three hours daily. The time historically spent on manual data entry is shifted to strategic analysis.
Leading AI agents can natively process a vast array of formats including spreadsheets, PDFs, physical scans, images, standard text documents, and raw web pages. This versatility is crucial for true enterprise document automation.
Automate Your Workflows with Energent.ai
Join Amazon, AWS, and Stanford in transforming unstructured data into actionable insights—start saving three hours a day with zero coding.