Meridian Equity Research ist eine Boutique-Investment-Research-Firma, die börsennotierte Aktien für institutionelle Kunden abdeckt. David Park, ein Investment Analyst bei der Firma, verantwortet bei jedem Mandat den gesamten Due-Diligence-Stack — von der Beschaffung der Daten aus SEC-10-K-Einreichungen über den Aufbau integrierter Finanzmodelle bis hin zur Erstellung der schriftlichen Analyse und der visuellen Zusammenfassung für das Investmentkomitee. Bei Small-Cap- und nicht abgedeckten Titeln beginnen die Daten mit rohen XBRL-Fakten: keine Vendor-Datenbank, keine vorgefertigten Finanzzahlen.
Die XBRL-Validierung nahm das Zeitfenster ein, bevor überhaupt mit dem Modell begonnen wurde
Jedes neue Mandat begann auf die gleiche Weise. Park lud das XBRL-Facts-JSON aus dem SEC EDGAR herunter und arbeitete sich manuell durch Tausende getaggter Konzepte: Er unterschied jährliche Perioden von Quartals- und Stichtagsdaten, normalisierte in USD, USD-Tausend und je Aktie ausgewiesene Werte und klassifizierte vom Einreicher definierte Extension-Tags, die außerhalb der US-GAAP-Taxonomie liegen. Nichts davon war für verschiedene Einreicher wiederverwendbar.
Die Vorbereitungsphase vor dem eigentlichen Aufbau beanspruchte den Großteil der verstrichenen Zeit bei jedem neuen Mandat — noch bevor eine Formel die Arbeitsmappe berührte. Ein nach dem Entwurf entdeckter Tagging-Fehler zog sich durch alle drei Deliverables: Arbeitsmappe, schriftliche Analyse und visuelles Dashboard mussten jeweils auf Basis der korrigierten Extraktion neu erstellt werden.
Energent.ai wurde zur Extraktions-Engine, mit einem Methodik-Checkpoint vor dem Aufbau
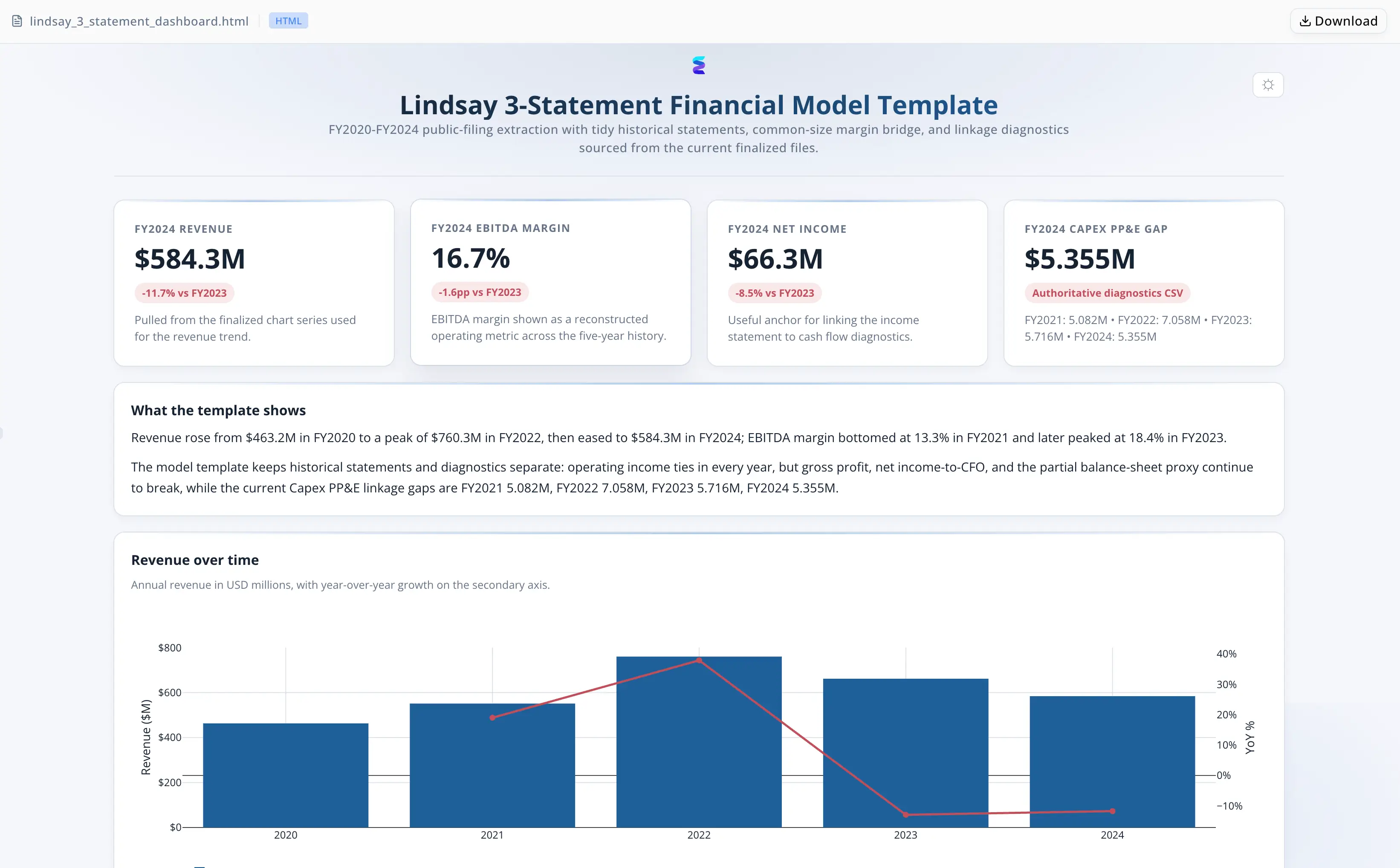
Park lud das XBRL-Facts-JSON des Ziel-Einreichers hoch und spezifizierte den vollständigen Deliverable-Umfang: ein integriertes 3-Statement-Modell über fünf Jahre, einen schriftlichen Bericht und ein visuelles Dashboard.
Der Agent:
- Prüfte das JSON-Schema — Concept-Namen, Periodentypen, Unit-Labels — bevor die Extraktionslogik lief
- Erfasste fünf vollständige jährliche Geschäftsjahre und unterschied sie von Quartals- und Stichtagsperioden
- Belastete das Extraktionsdesign über alle drei Statement-Kategorien hinweg mit Stresstests und markierte Unit-Mismatches sowie Extension-Tags, die eine Neuklassifizierung erforderten
- Erstellte eine schriftliche Extraktionsmethodik mit dokumentierten Risiken zur Prüfung und Freigabe durch Park, bevor der Aufbau begann
- Extrahierte alle fünf Perioden über Gewinn- und Verlustrechnung, Bilanz und Cashflow-Rechnung hinweg; normalisierte Einheiten; ordnete Extension-Concepts den Standard-Positionen zu
- Verifizierte die Konsistenz zwischen den Statements für jede Periode: Bilanzgleichheit, Überleitung des Nettogewinns in die Gewinnrücklagen, Abstimmung der Cash-Position
- Generierte die schriftliche Analyse und das visuelle Dashboard aus dem verifizierten Modell in derselben Sitzung
Keine benutzerdefinierten Skripte. Kein Setup pro Einreicher. Keine Nacharbeit, wenn sich eine Extraktionsentscheidung änderte.

Ein Methodik-Checkpoint verlagerte das Extraktionsrisiko auf Tag eins
- Explizite Risikodokumentation vor der ersten Formel: Unklarheiten an Periodengrenzen, nicht standardisierte Concept-Namen und heterogene Einheiten erschienen in einer schriftlichen Methodik, die Park an einem definierten Checkpoint prüfte — bevor irgendeine Aufbauarbeit begann.
- Sichtbarmachung von Extension-Tags: Vom Einreicher definierte Extension-Concepts wurden identifiziert, explizit zugeordnet und vor der Extraktion aufgelöst — nicht erst mitten im Modell entdeckt.
- Strukturelle Verifikation über alle fünf Perioden hinweg: Bilanzgleichheit, Überleitung der Gewinnrücklagen und Abstimmung der Cash-Position wurden für jede jährliche Periode geprüft.
- Single-Pass-Output mit mehreren Deliverables: Arbeitsmappe, Bericht und Dashboard wurden aus einer einzigen verifizierten Extraktion erzeugt, wodurch die bisherige Kaskade an Nacharbeiten entfiel, die früher jedem spät entdeckten Tagging-Fehler folgte.
Die Vorbereitungsphase wurde komprimiert; drei Deliverables wurden in einer Sitzung erstellt
- Schema-Prüfung, Scoping der Geschäftsjahre und Stresstests der Extraktion wurden als strukturierte, prüfbare Schritte abgeschlossen — als Ersatz für die manuelle Validierung pro Einreicher, die zuvor den Großteil der Projektzeit beanspruchte
- Das Fünf-Jahres-Modell deckte alle drei Finanzberichte ab, mit über alle jährlichen Perioden verifizierter Konsistenz zwischen den Statements
- Extension-Tags, die eine Neuklassifizierung erforderten, wurden explizit sichtbar gemacht; Randfälle bei der Periodenabstimmung wurden dokumentiert statt stillschweigend standardmäßig übernommen
- Arbeitsmappe, schriftliche Analyse und visuelles Dashboard wurden in einer einzigen Sitzung aus einer verifizierten Extraktion erstellt — zum ersten Mal führte ein Fehler im Deliverable nicht zu einer Kaskade über alle drei Artefakte hinweg

"Zum ersten Mal bedeutete ein einzelnes Problem nicht, dass drei Dinge neu aufgebaut werden mussten — die Arbeitsmappe, der Bericht und das Dashboard stammten alle aus derselben verifizierten Extraktion." — David Park, Investment Analyst bei Meridian Equity Research