Clearpoint Financial Services verarbeitet pro Monat Zehntausende von Karten- und ACH-Transaktionen. Rachel Torres sitzt an der Schnittstelle von Accounting und Risk — sie stellt sicher, dass gebuchte Belastungen den autorisierten Beträgen entsprechen, dass die Saldenprüfungen beim Clearing bestanden wurden und dass keine doppelten Belastungen durchgerutscht sind. Das Team verantwortet den gesamten Abstimmungsprozess intern, einschließlich der Definition von Ausnahmen und der Audit-Fähigkeit.
Alte Schwellenwerte und manuelle Filterläufe ließen sich nicht auf 50,000 Datensätze skalieren
Der Abstimmungsprozess des Teams basierte auf einem heruntergeladenen Bank-Export, Pivot-Tabellen und hart codierten Filtergrenzen, die von einer früheren Analystin übernommen worden waren. Vier unterschiedliche Ausnahmekategorien erforderten separate manuelle Durchläufe durch die Daten. Die High-Value-Grenze war ein pauschaler Dollarbetrag, der zwei Jahre zuvor festgelegt worden war — ohne statistische Grundlage, ohne Aktualisierungsmechanismus. Verknüpfungen für Authentifizierungsrisiken liefen bei diesem Datenvolumen schlecht. Prüfungen auf Buchungsabweichungen erforderten die Identifizierung von Soll-Buchungen, die trotz unzureichender Kontosalden freigegeben wurden. Die Erkennung doppelter Belastungen verlangte eine Deduplizierungslogik auf Zeilenebene, die die Tabellenkalkulation in diesem Umfang nicht zuverlässig ausführen konnte. Verschärft wurde das Problem dadurch, dass über 87 Prozent der Datensätze keinen Zeitanteil im Transaktionszeitstempel hatten, standardmäßig auf Mitternacht (00:00) fielen und damit die Betrugserkennung außerhalb der Geschäftszeiten vollständig blockierten. Eine interne Audit-Prüfung verschärfte den Druck zusätzlich: Das Komitee stufte die pauschale Dollargrenze als statistisch nicht begründet ein und verlangte für jede Ausnahmekategorie eine dokumentierte Herleitung.
Energent.ai wurde zur statistischen Abstimmungs-Engine
Torres lud die CSV-Datei mit 50,000 Datensätzen direkt in Energent.ai hoch. In einer einzigen Sitzung:
- prüfte der Agent das Schema und bestätigte die Spaltentypen, bevor er irgendeinen Analysecode schrieb
- berechnete er den Mittelwert ($297.87) und die Standardabweichung der Transaktionsbeträge über den gesamten Datensatz
- leitete er die High-Value-Schwelle bei $1,176.33 mithilfe eines Z-Score-Schwellenwerts von 3 Standardabweichungen ab — ein Wert, der sich in jedem Zyklus aus dem neuen Batch neu berechnen lässt
- glich er die Anzahl der Login-Versuche ab, um Transaktionen mit Authentifizierungsrisiko bei den obersten 1 Prozent der Reibungsereignisse zu isolieren
- verglich er Soll-Buchungen mit den erfassten Kontosalden, um freigegebene, aber unzureichend gedeckte Datensätze zu markieren
- erkannte er die 87-prozentige Lücke bei den fehlenden Zeitstempeln mitten in der Sitzung und dokumentierte sie als konkreten Defektbericht, statt die Ergebnisse stillschweigend zu verzerren
- erzeugte er ein interaktives HTML-Dashboard für Ausnahmen, nach Schweregrad sortiert und als eigenständige Datei direkt verteilbar
Keine Datenpipeline. Keine BI-Tool-Konfiguration. Kein Übergabepunkt zwischen Systemen.
Nicht nur sauberere Berichte, sondern eine Herleitung der Schwellenwerte
- Audit-sichere Logik. Die Schwelle von $1,176.33 wurde aus dem Live-Datensatz abgeleitet und Schritt für Schritt erklärt, wodurch die Dokumentationsanforderung des Audit-Komitees direkt erfüllt wurde.
- Datenqualität explizit sichtbar gemacht. Der Agent markierte den Befund der 87-prozentigen Lücke bei den fehlenden Zeitstempeln, statt stillschweigend auf einen Standardwert auszuweichen — so erhielt das Team einen quantifizierten Defektbericht für den Verantwortlichen der Ingestion-Pipeline.
- Vier Queues, ein Durchlauf. Betragsabweichungen, Authentifizierungsrisiken, Buchungsabweichungen und doppelte Belastungen wurden in einer einzigen Sitzung erfasst und ersetzten vier separate manuelle Filterläufe.
- Von Grund auf reproduzierbar. Dieselbe statistische Logik wird bei jedem neuen Batch-Export erneut ausgeführt, ohne Tabellenkalkulationsformeln neu aufzubauen.

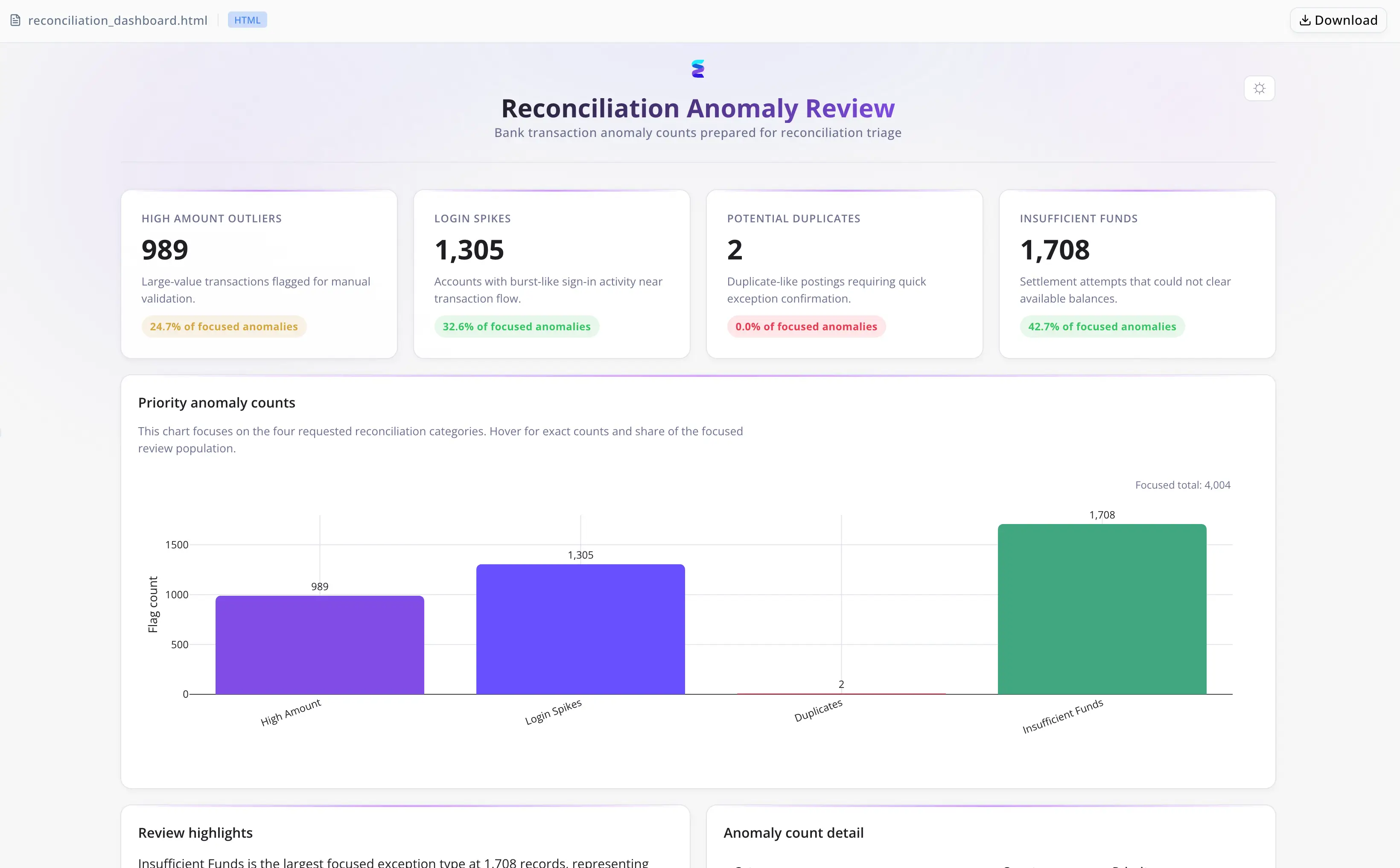
4,004 Ausnahmen in einer Sitzung isoliert, priorisiert und dokumentiert
- 4,004 Ausnahmen insgesamt aufgedeckt — rund 8 Prozent des 50,000-Datensatz-Batches
- 989 Betragsabweichungen oberhalb von $1,176.33 markiert, entsprechend den obersten ~2 Prozent des Transaktionsvolumens
- 1,305 Transaktionen mit Authentifizierungsrisiko bei 4 oder mehr Login-Versuchen pro Transaktion isoliert
- 1,708 Buchungsabweichungen identifiziert, bei denen Soll-Buchungen trotz unzureichender Kontosalden freigegeben wurden — die größte einzelne Ausnahmewarteschlange
- 2 bestätigte doppelte Belastungen sofort als Rückerstattungsfälle mit höchster Priorität eskaliert
- 87-prozentige Zeitstempel-Lücke dokumentiert, wodurch die Roadmap für die Betrugserkennung außerhalb der Geschäftszeiten bis zu einer Behebung der vorgelagerten Ingestion blockiert wurde
"Die Anzahl der Buchungsabweichungen war etwas, das wir in diesem Umfang noch nie sauber isoliert hatten. Jetzt haben wir eine Zahl, die wir vertreten können — und einen Prozess, den wir im nächsten Quartal erneut ausführen können, ohne die Formeln anzufassen." — Rachel Torres, Reconciliation Analyst bei Clearpoint Financial Services