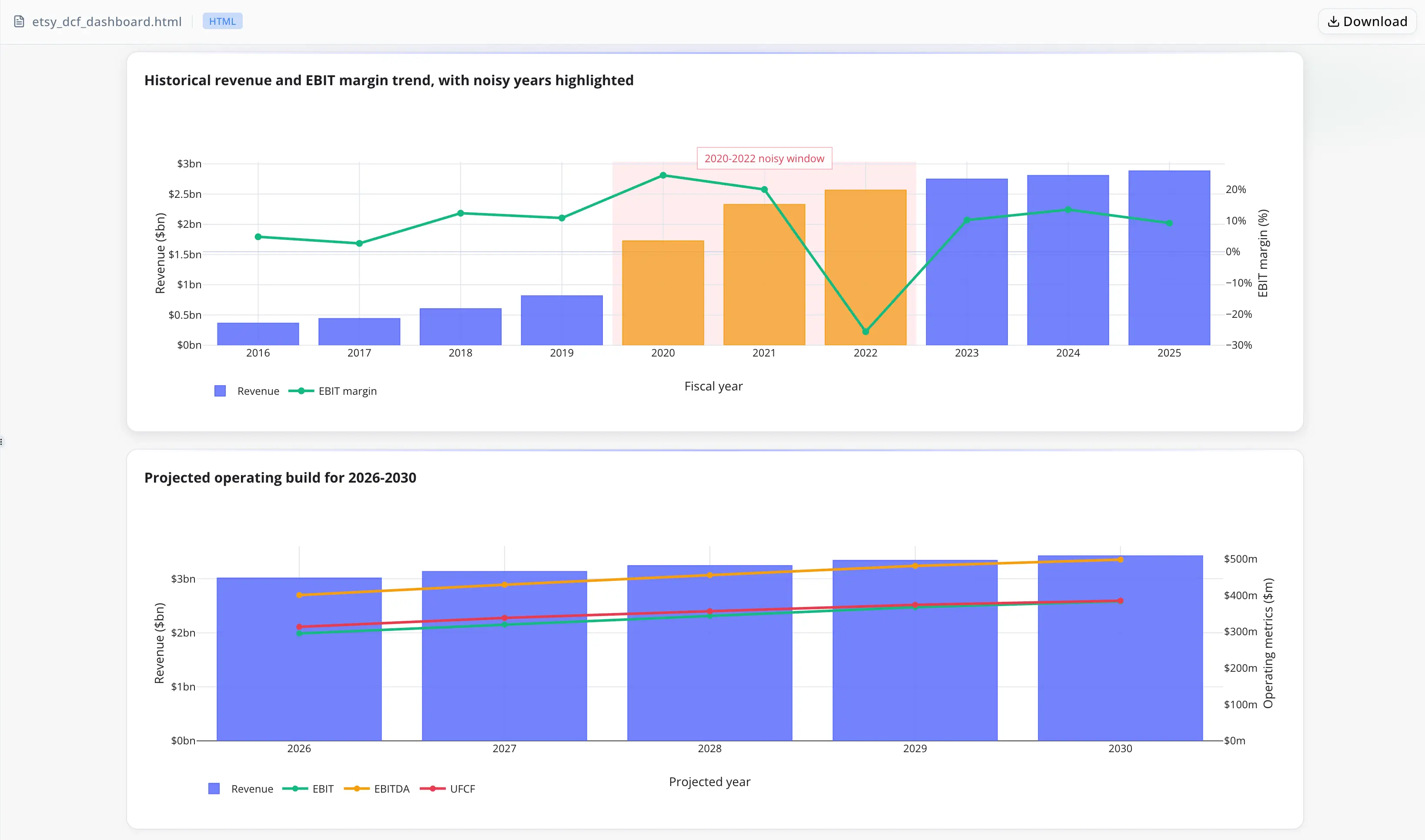
Cascade Capital Advisors ist eine Investmentfirma im Mid-Market-Segment, in der Analysten fünfjährige operative DCF-Modelle end-to-end verantworten. Mercers Team bezieht Finanzdaten aus SEC-EDGAR-Filings und liefert Excel-Workbooks mit NPV- und IRR-Ergebnissen an Investmentkomitees – zunehmend mit 48-Stunden-Umsetzungsfristen.
Mehrstündige Taxonomie-Recherchen gingen jedem 10-K-Modellaufbau voraus
Jedes neue Filing-Modell begann auf die gleiche Weise: die SEC-Company-Facts-JSON herunterladen, eine leere Vorlage öffnen und mehrere Stunden damit verbringen, EDGAR-Taxonomie-Tags manuell den sechs Modellierungskategorien zuzuordnen — Umsatz, EBIT, D&A, Capex, effektiver Steuersatz und Working Capital. D&A tauchte in der Gewinn- und Verlustrechnung, der Kapitalflussrechnung und den ergänzenden Fußnoten auf — oft redundant. Bei Capex musste bestätigt werden, dass der Tag keine akquisitionsbezogenen Ausgaben enthielt.
Der Engpass lag bei den Senior Analysts. Zu bestimmen, welche EDGAR-Tags wirtschaftlich verwendbar waren, erforderte ein filing-spezifisches Urteilsvermögen, das Junior-Teammitglieder nicht liefern konnten. Deal-Zeitpläne verkürzten sich von einer Woche auf 48 Stunden. In der Berichtssaison kamen mehrere Filings in derselben Woche herein. Der manuelle Ansatz ließ sich nicht skalieren.
Energent.ai wurde zur Datenebene vor dem Modell
Der Analyst lädt die rohe SEC-Company-Facts-JSON hoch — keine Formatkonvertierung, kein Preprocessing. Der Agent deckt in einer einzigen Sitzung fünf strukturierte Schritte ab:
- Schema und Abdeckung geprüft — verfügbare Geschäftsjahre bestätigt und Lücken in der Historie vor jeder Modellierungsentscheidung markiert
- Taxonomie über alle sechs Kategorien hinweg zugeordnet — Kandidaten-Tags identifiziert und ihre Abdeckung über die Berichtsperioden hinweg bewertet
- Operating Drivers triagiert — verwendbare Positionen von fehlenden oder wirtschaftlich irreführenden Tags getrennt
- Zwei tragfähige UFCF-Architekturen identifiziert mit klaren Abwägungen, die auf der tatsächlichen Filing-Abdeckung basieren
- Das Excel-Workbook erstellt — fünfjährige operative Prognose, UFCF-Wasserfall, NPV- und IRR-Ergebnisse sowie komiteegeeignete Visualisierungen
Kein manuelles Suchen nach Tags. Keine Vorlage, bevor die Daten verstanden waren. Keine Architekturentscheidung, die erst in die Zellbefüllung verschoben wurde.

Architekturentscheidung zuerst, filing-spezifische Abwägungen transparent gemacht
- Zwei UFCF-Build-Pfade vor jeder Ausgabe. Der Agent identifizierte konkurrierende Architekturen, die zu dem passten, was dieses konkrete 10-K tatsächlich berichtete — nicht zu einer generischen Vorlage — sodass die strukturelle Entscheidung getroffen wurde, bevor auch nur eine Zelle befüllt war.
- Gleichzeitige Analyse über mehrere Statements hinweg. Umsatz, EBIT, D&A, Capex, Steuern und Working Capital wurden in einem einzigen Durchlauf bewertet, wobei Gewinn- und Verlustrechnung, Bilanz und Kapitalflussrechnung auf Lücken und Überschneidungen abgeglichen wurden.
- Explizite Hinweise auf irreführende Tags. Fehlende Tags für Veränderungen im Working Capital und Capex-Positionen inklusive Akquisitionen wurden angezeigt, bevor sie in eine Zelle gelangten — nicht erst bei der nachgelagerten Abstimmung entdeckt.
- Senior-Kapazität auf Urteilsvermögen umgelenkt. Die Architekturentscheidung lag als strukturierte Entscheidung mit bereits erläuterten Abwägungen vor — sodass die Analystenzeit für Auswahl und Annahmenbildung genutzt wurde, nicht für Datenaufbereitung.
Wie David Mercer es im Tagesgeschäft einsetzt
- Die SEC-Company-Facts-JSON in die Energent.ai-Sitzung hochladen.
- Den Schema- und Abdeckungs-Check prüfen; Modellierungsjahre und eventuelle Historienlücken bestätigen.
- Die beiden UFCF-Architekturoptionen gegen den vorgesehenen Einsatzzweck des Modells bewerten.
- Eine Architektur auswählen; der Agent erstellt die fünfjährige Prognose, den UFCF-Wasserfall und die DCF-Ergebnisse in Excel.
- NPV- und IRR-Ergebnisse vor der Präsentation im Komitee auf Konsistenz der Annahmen prüfen.
Die Taxonomiezuordnung wechselte von einer mehrstündigen Aufgabe zu einer Sitzung
- Alle sechs Modellierungskategorien wurden in einer einzigen Sitzung aus der rohen JSON zugeordnet — und damit die manuelle Taxonomie-Recherche eliminiert, die jedem neuen Filing-Modellaufbau vorausging.
- Zwei tragfähige UFCF-Architekturen wurden mit Abwägungen aufgezeigt, bevor der Analyst eine Vorlage berührte.
- Der Architekturentscheidungszeitpunkt wurde erreicht, bevor irgendeine Zelle befüllt war, wodurch das versteckte Abstimmungsrisiko entfiel, das bei manuellen Builds oft erst in der Mitte sichtbar wurde.
- Das finale Excel-Workbook enthielt ein strukturiertes DCF-Modell mit NPV- und IRR-Ergebnissen sowie komiteegeeigneten Visualisierungen.

"Die Taxonomie-Matrix, die der Agent erstellt hat — abgedeckte Tags, fehlende Tags, markierte Positionen über alle sechs Kategorien hinweg — ersetzte die mentale Checkliste, die ich mir über Jahre mit EDGAR-Erfahrung aufgebaut hatte. Sie ist jetzt das Arbeitsdokument für die Architektur-Diskussion, bevor wir überhaupt etwas bauen." — David Mercer, Senior Analyst bei Cascade Capital Advisors