Meridian Apparel ist eine mittelgroße Konsumgütermarke, die von Fabriken im Ausland in mehreren Regionen bezieht. Zwei bis drei Procurement-Analysten gleichen jede eingehende Lieferantenrechnung mit der offenen PO-Datenbank und der Vendor-Master-Liste des Unternehmens ab, bevor die Daten in Finanz- und Bestandssysteme fließen. Fehler in der Master-Arbeitsmappe wirken sich direkt auf Berichte aus, die vom CFO geprüft werden.
Seitenumbrüche, zusammengeführte Zellen und versteckte PO-Nummern beschädigten das Master-Sheet unbemerkt
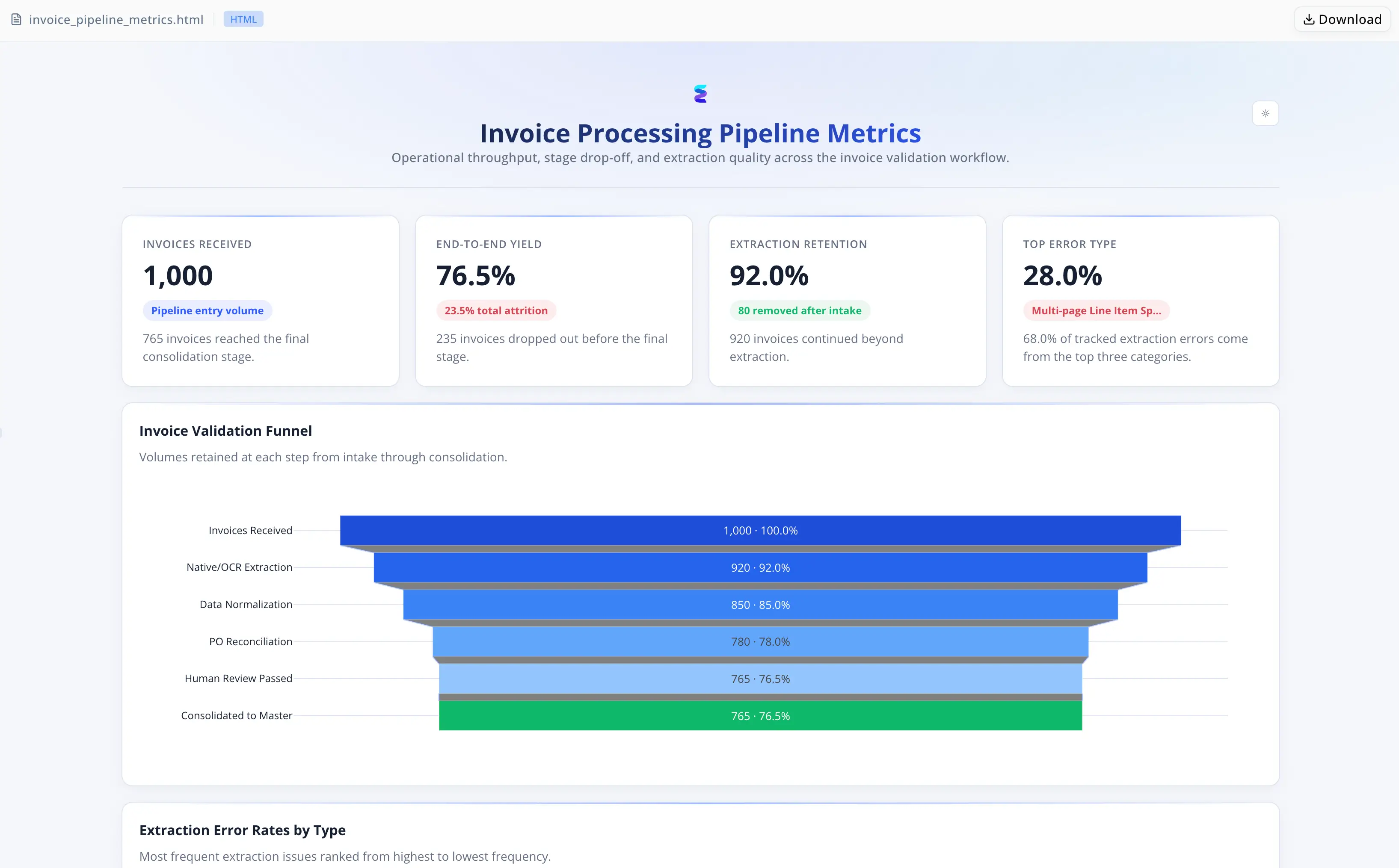
In jedem Monatszyklus verarbeitete das Team Dutzende Rechnungen mit bis zu 50 Positionen — eingehend als gescannte PDFs, native digitale Dateien und Excel-Arbeitsmappen mit zusammengeführten Zellen. Die Konsolidierung war fast vollständig manuell: jede Rechnung öffnen, visuell auslesen, jede Zeile per Hand erfassen.
Drei Fehlerquellen verstärkten sich gegenseitig. Seitenumbrüche erzeugten verwaiste SKUs mit null Mengen — Datensätze, die vollständig aussahen, strukturell aber beschädigt waren. Zusammengeführte Excel-Vorlagen der Lieferanten führten zu leeren Zeilen, die Analysten uneinheitlich ausfüllten. Lieferanten, die PO-Referenzen in Freitext-Headern versteckten — „Re: Your order 45992-A“ — lösten PO-Nichtzugeordnet-Markierungen und separate Korrekturschleifen aus. Die mathematische Abstimmung erkannte rund 90% der OCR-Fehler bei geteilten Zeilen, allerdings erst, nachdem die Datenerfassung bereits abgeschlossen war. Ein saisonaler Anlauf, drei bis fünf neue Fabriken an Bord zu holen, und eine Finanzinitiative, die Zahlungsziele von net-45 auf net-30 verkürzte, brachen das informelle Skalierungsmodell: Rechnungsbatches mussten nun innerhalb eines einzigen Arbeitstags validiert werden.
Energent.ai wurde zur durchgängigen Konsolidierungspipeline
Das Team evaluierte eine erweiterte Excel-Makro-Suite und eine eigenständige OCR-Punktlösung. Beide behandelten Erfassung und Validierung als getrennte Schritte; keine der beiden konnte extrahierte Werte mit dem Vendor-Master oder der offenen PO-Datenbank abgleichen. Energent.ai übernahm die komplette Pipeline in einer einzigen Agenten-Session:
- Leitete jedes Dokument weiter anhand des Vorhandenseins einer Textebene — native PDFs wurden direkt verarbeitet, gescannte PDFs per Vision-Extraktion — und eliminierte so Koordinatenabweichungen
- Extrahierte Positionen über Seitenumbrüche hinweg, ausgerichtet an Tabellenüberschriften statt an Seitenrändern
- Füllte zusammengeführte Zellspalten vorwärts auf — Fabrikname, Style-Code, PO-Nummer — um der Lieferantenlogik zu entsprechen
- Stellte versteckte PO-Nummern wieder her per Regex über den gesamten Textblock und markierte wiederhergestellte Werte mit einem
source: text_recovery-Flag - Führte eine zweistufige Validierung vor dem Anhängen aus: Phase 1 normalisierte Datums- und Zahlenfelder; Phase 2 glich den Vendor-Master ab, validierte offene POs und führte Prüfungen auf Zeilen- und Rechnungsebene durch
- Stellte Ausnahmen nach Fehlercode bereit —
vendor_unmatched,math_fail,po_not_found,confidence_below_85pct— in einem dedizierten Tab, ohne validierte Daten anzutasten
Keine benutzerdefinierte OCR-Pipeline. Kein separates Validierungsskript. Keine fragile Makro-Suite, die gewartet werden musste.
Die Validierung wurde vor das Anhängen an das Master-Sheet verlagert
- Confidence-Gating bei 85%. Datensätze unterhalb des Schwellenwerts erreichen das Master-Sheet nie — sie landen im Staging-Tab mit angehängtem Fehlergrund.
- Plausibilitätsprüfungen vor statt nachher. Die Abstimmung auf Zeilen- und Rechnungsebene läuft als Teil der automatisierten Pipeline und fängt ~90% der Fehler bei geteilten Zeilen ab, bevor sie die Arbeitsmappe beschädigen.
- Formatunabhängige Weiterleitung. Gescannte PDFs, native PDFs und Excel-Arbeitsmappen laufen in derselben Session; der Dokumenttyp bestimmt den Extraktionspfad, nicht das Urteil des Analysten.
- Kommentierte Ausnahmeliste. Jeder markierte Datensatz trägt einen konkreten Fehlercode und ersetzt informelle Ad-hoc-Korrekturen durch eine priorisierte Prüfliste.

Zwei bis drei Analystentage pro Batch wurden auf eine reine Ausnahmeprüfung reduziert
- Batches mit zehn Rechnungen und jeweils 30 bis 50 Positionen erforderten zuvor zwei bis drei Analystentage; Straight-through Processing verarbeitet nun alle Datensätze, die Phase-2-Abstimmung bestehen, ohne Eingriff durch Analysten
- Forward-Fill-Normalisierung und Regex-basierte PO-Wiederherstellung beseitigten zwei Kategorien stiller Extraktionsfehler über alle Lieferantenvorlagen hinweg
- Der beschriftete Staging-Tab — jede Ausnahme mit einem konkreten Fehlercode versehen — ersetzte einen informellen Korrekturprozess durch eine klare, umsetzbare Prüfliste
"Was sich geändert hat, ist, dass wir Validierung nicht mehr als etwas behandeln, das nach der Datenerfassung passiert. Ausnahmen landen in einem Staging-Tab, und der Grund ist bereits hinterlegt — wir wissen genau, was wir korrigieren müssen und warum, bevor wir eingreifen." — Priya Sharma, Procurement Operations Lead bei Meridian Apparel