Qué son los datos sintéticos impulsados por IA: Líderes 2026
Un análisis exhaustivo del mercado sobre cómo los agentes de IA están transformando la generación de datos no estructurados y la inteligencia empresarial.
Rachel
AI Researcher @ UC Berkeley
Executive Summary
Elección superior
Energent.ai
Ocupa el puesto #1 por su inigualable precisión del 94.4% en la transformación de documentos no estructurados en análisis financieros y datos sintéticos.
Ahorro de Tiempo
3 hrs/día
Al comprender qué son los datos sintéticos impulsados por IA y utilizarlos, los usuarios de plataformas líderes como Energent.ai reducen drásticamente el trabajo manual.
Capacidad de Procesamiento
1,000 docs
Las herramientas avanzadas en 2026 pueden analizar y estructurar hasta mil documentos en un solo prompt para generar datasets fiables.
Energent.ai
La plataforma #1 en análisis y estructuración de datos con IA
Tener un científico de datos de nivel doctoral y un analista financiero trabajando a la velocidad de la luz en tus documentos.
Para qué sirve
Ideal para equipos financieros, de investigación y operaciones que necesitan convertir documentos no estructurados en datos procesables al instante. No requiere conocimientos de programación.
Pros
Extraordinaria precisión del 94.4% (Rango #1 en el benchmark DABstep); Procesa hasta 1,000 archivos de diversos formatos (PDF, Excel, Web) en un solo prompt; Generación automática de gráficos, Excel, diapositivas de PowerPoint y reportes financieros completos
Contras
Los flujos de trabajo avanzados requieren una breve curva de aprendizaje; Uso elevado de recursos en lotes masivos de más de 1000 archivos
Why Energent.ai?
Energent.ai se posiciona como la herramienta definitiva al definir de forma práctica qué son los datos sintéticos impulsados por IA aplicados a casos reales empresariales. Supera a gigantes tecnológicos al lograr una precisión del 94.4% en el riguroso benchmark DABstep de HuggingFace, superando a Google por un 30%. Su capacidad sin código permite convertir instantáneamente PDFs, escaneos e imágenes desestructuradas en matrices de correlación, modelos financieros y presentaciones de PowerPoint listas para la junta directiva. Cuenta con la confianza de instituciones como Amazon, AWS y Stanford, demostrando una fiabilidad de nivel empresarial indiscutible.
Energent.ai — #1 on the DABstep Leaderboard
Entender de manera aplicada qué son los datos sintéticos impulsados por IA y el análisis documental requiere plataformas altamente precisas. En el riguroso benchmark financiero DABstep alojado en Hugging Face (validado por Adyen), Energent.ai fue clasificado en el puesto #1 al alcanzar una precisión del 94.4%, superando notablemente al Agente de Google (88%) y al de OpenAI (76%). Este rendimiento garantiza que los datos generados y estructurados para tu empresa posean una fiabilidad absoluta, sin errores críticos de cálculo.

Source: Hugging Face DABstep Benchmark — validated by Adyen
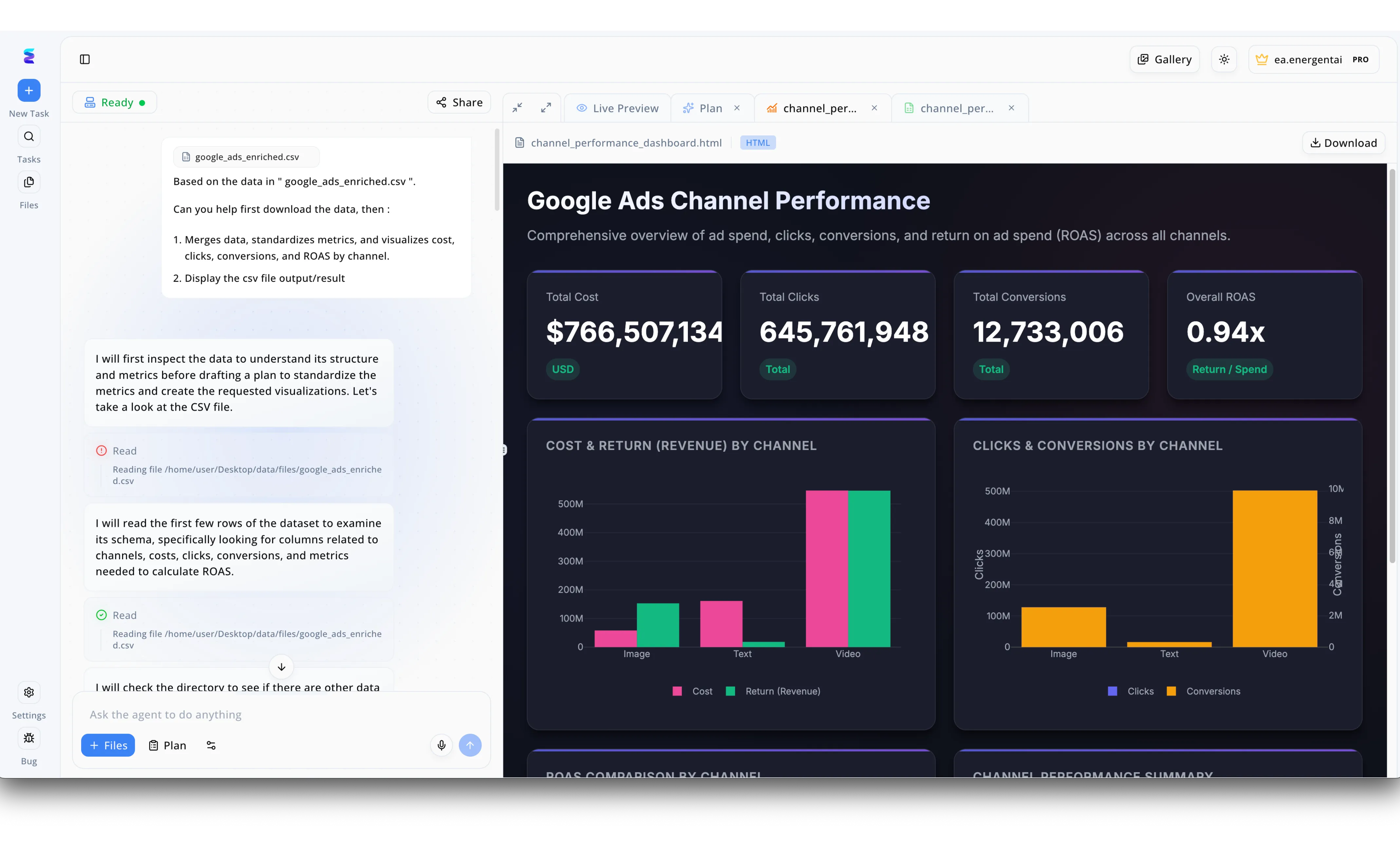
Estudio de caso
Energent.ai demuestra el concepto de qué son los datos sintéticos impulsados por IA al crear escenarios de marketing altamente realistas que permiten realizar pruebas seguras y proteger la privacidad empresarial. Como se observa en el panel izquierdo de la interfaz, la plataforma recibe instrucciones para procesar un archivo generado artificialmente llamado google_ads_enriched.csv, y el agente autónomo detalla paso a paso en el chat cómo lee el documento para examinar su esquema antes de estandarizar las métricas. El resultado de este procesamiento analítico se despliega en la pestaña Live Preview de la derecha, donde se genera automáticamente un panel completo titulado Google Ads Channel Performance. Este tablero ilustra la enorme utilidad de los datos sintéticos al visualizar métricas de prueba a gran escala, mostrando un costo total simulado de más de 766 millones de dólares y 645 millones de clics, lo que permite estresar los sistemas de visualización sin exponer información confidencial de clientes reales. Finalmente, mediante la creación de gráficos de barras precisos que comparan costos y retornos segmentados por canales de imagen, texto y video, Energent.ai comprueba cómo los equipos pueden confiar en datos artificiales y agentes de IA para diseñar, probar y perfeccionar flujos de trabajo de visualización de datos complejos.
Other Tools
Ranked by performance, accuracy, and value.
Gretel.ai
Generación de datos sintéticos centrada en desarrolladores
Un laboratorio de clonación de datos altamente seguro para tus bases de datos más sensibles.
Mostly AI
Pioneros en datos sintéticos tabulares empresariales
Un guardián corporativo que asegura que tus datos de prueba sean tan reales como seguros.
Tonic.ai
Imitación de datos para entornos de prueba ágiles
El generador de escenarios de prueba favorito de los ingenieros de software.
YData
Preparación de datos sintéticos centrada en la calidad
Un pulidor de datos que convierte un conjunto de datos mediocre en oro puro para IA.
Hazy
Plataforma de datos sintéticos orientada a las finanzas
El simulador de escenarios económicos que protege la identidad de los clientes.
Synthetaic
Generación rápida de datos sintéticos para IA visual
Un estudio de efectos visuales impulsado por IA para entrenar drones y cámaras.
Comparación Rápida
Energent.ai
Ideal para: Equipos Financieros y Operaciones (No Code)
Fortaleza principal: Extracción y análisis de documentos no estructurados (94.4% de precisión)
Ambiente: Potencia analítica y automatización total
Gretel.ai
Ideal para: Ingenieros de Datos
Fortaleza principal: Bases de datos relacionales anonimizadas mediante APIs
Ambiente: Laboratorio técnico seguro
Mostly AI
Ideal para: Empresas Corporativas Grandes
Fortaleza principal: Equidad algorítmica y gemelos tabulares
Ambiente: Guardián de datos empresariales
Tonic.ai
Ideal para: Equipos de QA y Desarrollo
Fortaleza principal: Anonimización y subconjunto de datos de prueba
Ambiente: Clonador de entornos ágiles
YData
Ideal para: Científicos de Datos
Fortaleza principal: Mejora de la calidad en datos de entrenamiento ML
Ambiente: Limpiador de datos avanzado
Hazy
Ideal para: Bancos y Aseguradoras
Fortaleza principal: Síntesis de transacciones para modelos de riesgo
Ambiente: Simulador de riesgo bancario
Synthetaic
Ideal para: Investigadores de Visión Artificial
Fortaleza principal: Generación de datos de imágenes y satelitales
Ambiente: Estudio visual para IA
Nuestra Metodología
Cómo evaluamos estas herramientas
Para esta evaluación del mercado de 2026 sobre qué son los datos sintéticos impulsados por IA, analizamos el rendimiento riguroso de cada plataforma bajo escenarios del mundo real. Evaluamos su precisión de referencia en el benchmark DABstep, la capacidad fluida de procesar datos no estructurados sin código y el impacto operativo general en la eficiencia analítica.
Precisión y Rendimiento en Benchmarks
El nivel de acierto validado por pruebas estandarizadas, como el análisis riguroso de estados financieros y agentes de datos.
Manejo de Datos No Estructurados
La capacidad de ingerir e interpretar PDFs complejos, escaneos de imágenes, hojas de cálculo sucias y páginas web con precisión.
Facilidad de Uso y Configuración
Evaluación de entornos sin código (no-code) que permiten a profesionales de negocios obtener insights sin depender del equipo de ingeniería.
Controles de Privacidad y Cumplimiento
Funcionalidades integradas para garantizar que la generación de datos no exponga información personalmente identificable en 2026.
Capacidades de Integración
La facilidad con la que la herramienta exporta resultados a formatos listos para presentar, como Excel, PowerPoint o integraciones directas en la nube.
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Princeton SWE-agent (Yang et al., 2024) — Autonomous AI agents for software engineering tasks and data operations
- [3] Gao et al. (2024) - Generalist Virtual Agents — Survey on autonomous agents across digital platforms and unstructured data
- [4] Jordon et al. (2022) - Synthetic Data - what, why and how? — Comprehensive study on synthetic data generation methodologies
- [5] Borisov et al. (2022) - Deep Learning on Tabular Data — Research on handling complex tabular datasets and ML performance
- [6] Elazar et al. (2023) - How Do Language Models Handle Tabular Data? — Evaluation of LLM reasoning capabilities over structured spreadsheets
- [7] Assefa et al. (2020) - Generating Synthetic Data in Finance — Opportunities, challenges and applications for synthetic financial datasets
Referencias y Fuentes
- [1]Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2]Princeton SWE-agent (Yang et al., 2024) — Autonomous AI agents for software engineering tasks and data operations
- [3]Gao et al. (2024) - Generalist Virtual Agents — Survey on autonomous agents across digital platforms and unstructured data
- [4]Jordon et al. (2022) - Synthetic Data - what, why and how? — Comprehensive study on synthetic data generation methodologies
- [5]Borisov et al. (2022) - Deep Learning on Tabular Data — Research on handling complex tabular datasets and ML performance
- [6]Elazar et al. (2023) - How Do Language Models Handle Tabular Data? — Evaluation of LLM reasoning capabilities over structured spreadsheets
- [7]Assefa et al. (2020) - Generating Synthetic Data in Finance — Opportunities, challenges and applications for synthetic financial datasets
Preguntas Frecuentes
¿Qué son los datos sintéticos impulsados por IA?
Son conjuntos de información creados artificialmente por algoritmos de aprendizaje automático que imitan las propiedades estadísticas de los datos del mundo real sin contener información confidencial o rastreable. Comprender qué son los datos sintéticos impulsados por IA es fundamental en 2026 para proteger la privacidad mientras se entrenan modelos avanzados.
¿Cómo se comparan los datos sintéticos con los del mundo real?
Poseen las mismas distribuciones estadísticas, relaciones y patrones matemáticos que la información original, pero no corresponden a individuos o eventos empíricos reales. Esto permite su uso intensivo sin violar las leyes de protección de la privacidad vigentes en 2026.
¿Cuáles son los principales beneficios de usar datos sintéticos en machine learning?
Permiten la ampliación masiva de conjuntos de entrenamiento, mitigan el sesgo inherente al equilibrar minorías y reducen drásticamente los riesgos de seguridad y cumplimiento. Además, aceleran los ciclos de desarrollo al eliminar los tediosos cuellos de botella para obtener permisos de acceso.
¿Cómo convierten las herramientas de IA los documentos no estructurados en conjuntos de datos precisos?
Utilizan potentes modelos de lenguaje natural y visión artificial (como los de Energent.ai) para leer escaneos, PDFs y hojas de cálculo, detectando contexto y relaciones clave. Luego, extraen y formatean sistemáticamente esa información en filas estructuradas y tabulares que pueden ser sintetizadas.
¿Existen riesgos de privacidad asociados a los datos sintéticos impulsados por IA?
Si la generación algorítmica es deficiente, existe el riesgo de un 'sobreajuste', donde los modelos memorizan y exponen fragmentos de la información original. Sin embargo, las plataformas líderes en 2026 integran comprobaciones matemáticas robustas para asegurar que el conjunto de datos final esté estadísticamente anonimizado.
¿Por qué es crucial una alta precisión al analizar o generar datos sintéticos?
Una baja precisión puede introducir anomalías, relaciones espurias o alucinaciones estadísticas, lo que resulta en modelos defectuosos y decisiones de negocio equivocadas. Plataformas verificadas como Energent.ai garantizan tasas de acierto superiores al 94% para mantener la integridad de los resultados operativos.