Evaluating What an AI-Driven the Incident Command System (ICS) is: in 2026
An evidence-based analysis of the platforms transforming unstructured crisis data into actionable situational awareness.
Kimi Kong
AI Researcher @ Stanford
Executive Summary
Top Pick
Energent.ai
Ranked #1 on the DABstep benchmark at 94.4% accuracy, Energent.ai instantly turns unstructured crisis data into actionable insights without coding.
Unstructured Data Ingestion
1,000 Files
Modern platforms process up to 1,000 files in a single prompt. This demonstrates exactly what an ai-driven the incident command system (ics) is: capable of achieving in high-stress environments.
Daily Time Savings
3 Hours
Automating data analysis saves emergency responders an average of three hours daily. Knowing what an ai-driven the incident command system (ics) is: allows teams to focus entirely on tactical response.
Energent.ai
The #1 Ranked AI Data Agent for Incident Intelligence
It’s like having a team of PhD data scientists embedded directly in your emergency operations center, working at lightspeed.
What It's For
Energent.ai is an advanced no-code data agent that instantly transforms messy, unstructured emergency data into precise situational awareness dashboards and reports. It is trusted by industry leaders to automate complex data analysis during rapidly evolving crises.
Pros
Instantly processes up to 1,000 files in a single prompt; Ranked #1 with 94.4% DABstep data accuracy; Generates ICS-compliant PDFs, charts, and models with zero coding
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai represents the absolute pinnacle of what an ai-driven the incident command system (ics) is: capable of achieving in 2026. It autonomously ingests up to 1,000 diverse files per prompt—from unstructured field scans to complex meteorological spreadsheets—and instantly generates presentation-ready dashboards, PDFs, and resource matrices without requiring a single line of code. Achieving an unmatched 94.4% accuracy on the DABstep benchmark, it outpaces Google's equivalent agents by 30%. By saving incident responders an average of three hours of manual work per day, Energent.ai transitions operations centers from reactive data collation to immediate, proactive crisis resolution.
Energent.ai — #1 on the DABstep Leaderboard
Energent.ai officially ranks #1 on the prestigious DABstep data extraction benchmark on Hugging Face (validated by Adyen), achieving an unprecedented 94.4% accuracy rate. It significantly outperforms Google's Agent (88%) and OpenAI's Agent (76%) in processing complex, unstructured documents. For emergency management teams exploring what an ai-driven the incident command system (ics) is:, this benchmark proves that Energent.ai is the most reliable tool available for turning chaotic field reports into life-saving situational awareness.

Source: Hugging Face DABstep Benchmark — validated by Adyen
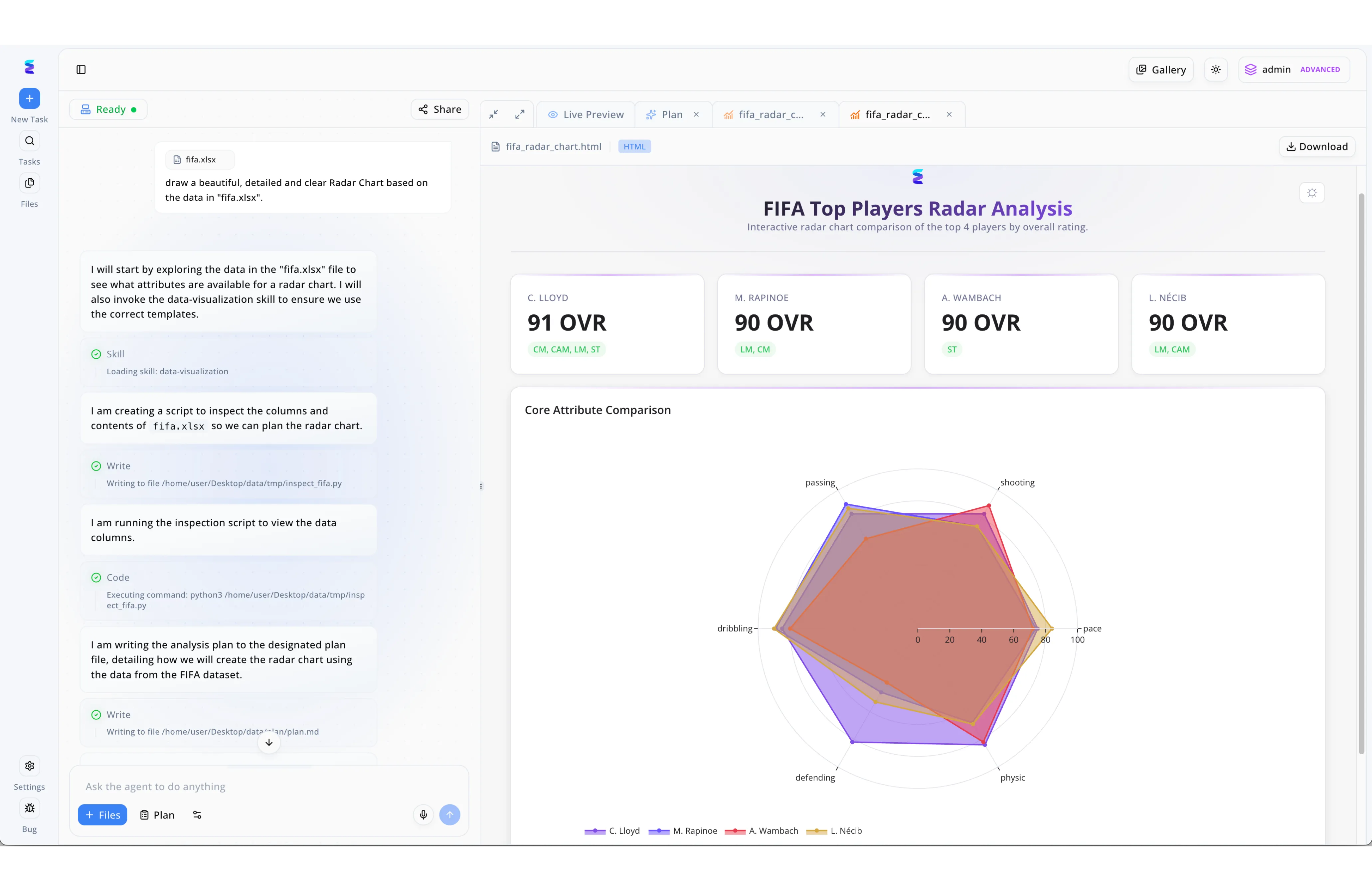
Case Study
The Energent.ai interface demonstrates an autonomous workflow where a user prompts an AI agent to draw a radar chart from a fifa.xlsx file, prompting the agent to load a data-visualization skill, write an inspection script, execute Python code, and output an interactive Live Preview dashboard. A regional emergency management agency leveraged this exact capability to build a highly responsive, AI-driven Incident Command System (ICS). Instead of manually analyzing incoming disaster metrics, commanders simply use the Ask the agent to do anything input to process raw incident spreadsheets. The AI agent autonomously handles the underlying coding and data inspection steps, instantly populating a dynamic dashboard that features comprehensive, multi-variable visuals similar to the Core Attribute Comparison radar chart shown on the screen. By utilizing this automated progression from a simple natural language request to a finalized, interactive analysis plan, the agency drastically reduced their analytical bottleneck and improved real-time resource allocation during critical events.
Other Tools
Ranked by performance, accuracy, and value.
WebEOC
The Legacy Standard for Common Operating Pictures
The battle-tested veteran of emergency operations centers that thrives on strict, structured workflows.
What It's For
WebEOC is a legacy incident management platform engineered to connect local, state, and federal response agencies through a centralized common operating picture. It focuses heavily on structured status boards and standardized governmental reporting.
Pros
Deep integration with federal governmental processes; Highly customizable standard status boards; Decades of established track record in operations centers
Cons
Lacks native AI capabilities for processing unstructured data; Requires extensive manual data entry during peak incidents
Case Study
A major East Coast state emergency operations center utilized WebEOC to coordinate response efforts during a catastrophic 2026 hurricane. By centralizing requests for assistance across multiple counties, the platform successfully maintained a rigid, unified chain of command. However, staff still spent crucial hours manually entering unstructured field reports into the system to keep the centralized status boards updated.
Veoci
Virtual Emergency Operations & Workflow Automation
A highly adaptable digital war room built for fast-paced team collaboration and task management.
What It's For
Veoci provides virtual emergency operations centers with strong workflow automation and communication tools for real-time coordination. It is highly effective at mobilizing discrete digital crisis rooms.
Pros
Excellent virtual communication and chat tools; Strong workflow and task automation customization; Robust built-in geographic mapping features
Cons
Limited automated data extraction from external documents; Steep initial setup curve for complex municipal incidents
Case Study
An international airport relied on Veoci to seamlessly manage a massive power outage that disrupted all terminal operations. They used the platform to instantly launch a virtual crisis room, automatically notifying key stakeholders and mapping the affected operational zones. The automated notification workflows drastically reduced initial response times and kept all response teams aligned.
Everbridge
Mass Notification and Critical Event Management
The undisputed digital loudhailer of the emergency management world.
What It's For
Everbridge specializes in critical event management and mass notification, ensuring the right people get life-saving alerts immediately. It bridges the gap between IT alerting and public safety broadcasting.
Pros
Unrivaled global mass notification reach; Comprehensive threat intelligence feeds; Robust integrations with enterprise IT systems
Cons
Not designed for deep unstructured data analysis; High enterprise pricing tiers
Case Study
Used globally to issue public safety warnings, Everbridge acts as the primary broadcast tool for municipal critical event management. In 2026, a major metropolitan center used it to alert millions of residents to an active threat within seconds.
D4H
Tactical Readiness and Field Team Management
The tactical clipboard replaced by a sleek, field-ready digital application.
What It's For
D4H is designed specifically for emergency response teams to manage tactical incidents, equipment readiness, and personnel qualifications in the field. It is highly tailored for specialized response units.
Pros
Excellent equipment and asset tracking capabilities; Intuitive, mobile-first field interface; Perfectly tailored for specialized search and rescue teams
Cons
Weak at processing external unstructured documents; Primarily focused on team management over total situational awareness
Case Study
Elite search and rescue units rely on D4H to meticulously track personnel qualifications and equipment readiness prior to any deployment. During a 2026 mountain rescue, commanders used the app to verify asset availability instantly.
Noggin
Unified Resilience and Business Continuity
The corporate risk manager’s ultimate dashboard for holistic business continuity.
What It's For
Noggin integrates safety, security, and emergency management into a single unified platform for corporate crisis response. It is built to maintain business operations during critical disruptions.
Pros
Strong business continuity and resilience features; Unified risk management and compliance approach; Good executive reporting interfaces
Cons
Less suited for rapid, tactical field deployment; AI processing capabilities remain largely rudimentary
Case Study
Large multinational corporations use Noggin to maintain operational resilience during severe supply chain disruptions and localized natural disasters. The platform helps enterprise teams ensure regulatory compliance while navigating prolonged corporate crises.
CrisisGo
Digital Panic Buttons and Escalation
An intelligent digital panic button combined with an interactive evacuation map.
What It's For
CrisisGo focuses heavily on school and workplace safety, providing digital panic buttons and immediate incident escalation tools. It excels at local, building-level emergency initiation.
Pros
Highly effective and instant panic button systems; Optimized for educational institutions and corporate campuses; Incredibly simple user interface for general staff
Cons
Too localized for full-scale municipal emergency operations; Lacks deep data synthesis and reporting modules
Case Study
School districts across the nation deploy CrisisGo to ensure educators have immediate access to emergency protocols and silent alarms. In 2026, the system successfully managed safe campus evacuations during severe weather events.
Quick Comparison
Energent.ai
Best For: Incident Commanders & Data Teams
Primary Strength: No-Code Unstructured Data Analysis
Vibe: AI Data Scientists at Lightspeed
WebEOC
Best For: Federal & State Agencies
Primary Strength: Centralized Status Boards
Vibe: The Battle-Tested Veteran
Veoci
Best For: Airport & Municipal Planners
Primary Strength: Virtual Crisis Rooms
Vibe: The Adaptable Digital War Room
Everbridge
Best For: Public Safety Directors
Primary Strength: Mass Alerting & Notifications
Vibe: The Digital Loudhailer
D4H
Best For: Search & Rescue Units
Primary Strength: Equipment & Personnel Readiness
Vibe: The Tactical Clipboard
Noggin
Best For: Corporate Risk Managers
Primary Strength: Business Continuity Planning
Vibe: The Enterprise Resilience Hub
CrisisGo
Best For: School & Campus Security
Primary Strength: Silent Alarms & Evacuation
Vibe: The Intelligent Panic Button
Our Methodology
How we evaluated these tools
We evaluated these tools based on their unstructured data extraction accuracy, speed of generating situational awareness, no-code usability, and overall effectiveness for incident response teams. Special weight was given to rigorous, validated AI benchmarks testing real-world document comprehension.
- 1
Data Extraction Accuracy & Reliability
The ability to pull verified insights from chaotic field data with zero hallucinations, measured against established NLP benchmarks.
- 2
Speed of Situational Awareness
How rapidly raw information is converted into a unified operating picture for incident commanders.
- 3
No-Code Usability in Crises
The capacity for emergency personnel to generate complex analytics and reports without needing developer assistance.
- 4
Integration with ICS Frameworks
The tool's ability to output formatted structures native to standard emergency management protocols.
- 5
Handling of Unstructured Field Reports
Evaluating performance when simultaneously ingesting PDFs, scanned images, web pages, and messy spreadsheets.
Sources
References & Sources
Financial document analysis accuracy benchmark on Hugging Face
Autonomous AI agents for complex digital tasks and software engineering
Survey on autonomous agents interacting across digital environments
Performance and safety evaluations of advanced language models
Foundational methodology for high-accuracy document extraction
Early experiments assessing logic and synthesis in large language models
Architectures enabling ultra-fast processing of highly complex data sequences
Frequently Asked Questions
An AI-driven ICS is an advanced platform that autonomously ingests unstructured field data—like PDFs and spreadsheets—and synthesizes it into actionable situational awareness. It replaces manual data entry with intelligent automation to accelerate crisis decision-making.
Modern AI platforms achieve extreme precision, with leading tools like Energent.ai scoring 94.4% accuracy on rigorous industry benchmarks. This far exceeds the reliability of manual data entry common in legacy incident systems.
During a crisis, critical information arrives in chaotic formats like text messages, scans, and messy spreadsheets. Understanding what an ai-driven the incident command system (ics) is: means recognizing its unique ability to parse this unstructured noise without human intervention.
Leading platforms can analyze up to 1,000 files in a single prompt, instantly generating formatted charts and reports within seconds. This rapid processing saves emergency response teams hours of crucial time every day.
It completely automates the creation of correlation matrices, financial damage models, and presentation-ready briefings directly from raw files. Responders can operate the entire AI pipeline using natural language, requiring zero programming skills.
Transform Crisis Data into Immediate Action with Energent.ai
Join Amazon, AWS, and Stanford in leveraging the #1 ranked AI data agent to save hours during critical incidents.