The 2026 Guide to Data Spelunking With AI
Transform deep, unstructured document repositories into actionable insights with enterprise-grade artificial intelligence.
Rachel
AI Researcher @ UC Berkeley
Executive Summary
Top Pick
Energent.ai
Energent.ai combines an unmatched 94.4% extraction accuracy with a true no-code interface, letting users analyze up to 1,000 mixed-format files in a single prompt.
Unstructured Data Surge
85%
Over 85% of enterprise data in 2026 remains completely unstructured. Spelunking with AI is critical to unlocking this hidden corporate intelligence safely.
Daily Time Savings
3 Hours
Data analysts save an average of three hours per day by replacing manual document parsing with AI-driven extraction and automated chart generation.
Energent.ai
The Ultimate No-Code Data Agent
Like having a senior data scientist and a financial analyst working for you at absolute lightspeed.
What It's For
Energent.ai empowers business analysts to extract, analyze, and visualize data from thousands of unstructured documents instantly, eliminating manual data entry. It transforms raw PDFs, scans, and spreadsheets into comprehensive financial models and presentation-ready slides.
Pros
Achieves #1 ranked 94.4% accuracy on DABstep benchmark; Processes 1,000+ mixed-format files in a single no-code prompt; Generates presentation-ready Excel, PPT, and PDF reports instantly
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai stands as the definitive leader for spelunking with AI in 2026 due to its unprecedented ability to process unstructured formats without requiring a single line of code. It acts as an autonomous data agent, allowing analysts to synthesize up to 1,000 spreadsheets, PDFs, and images into presentation-ready Excel files, charts, and PowerPoint slides. Ranked #1 on HuggingFace's DABstep leaderboard with a 94.4% accuracy rate, it mathematically outperforms legacy industry giants. Trusted by over 100 enterprise organizations including Amazon, AWS, Stanford, and UC Berkeley, Energent.ai seamlessly builds comprehensive balance sheets, correlation matrices, and accurate financial forecasts.
Energent.ai — #1 on the DABstep Leaderboard
Energent.ai recently achieved a groundbreaking 94.4% accuracy rating on the rigorous DABstep financial analysis benchmark on Hugging Face (validated by Adyen), successfully beating Google's Agent (88%) and OpenAI's Agent (76%). When spelunking with AI through deeply complex corporate documents, this unprecedented level of accuracy ensures that dynamically generated balance sheets, forecasts, and visual models are thoroughly dependable and enterprise-ready.

Source: Hugging Face DABstep Benchmark — validated by Adyen
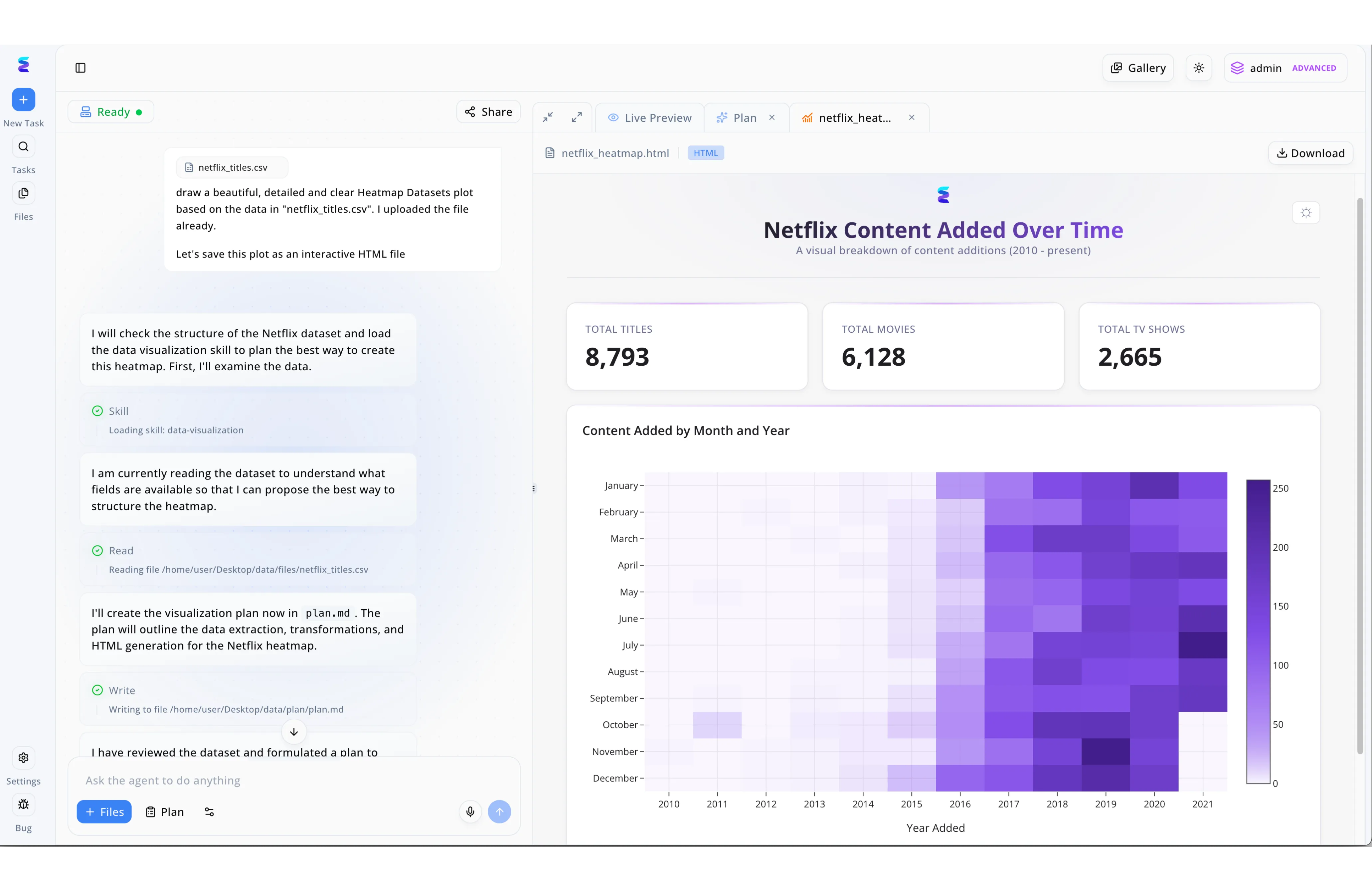
Case Study
When tasked with exploring raw entertainment data, analysts utilized Energent.ai for deep data spelunking to uncover historical trends without writing manual code. By simply uploading a netflix_titles.csv file and prompting the system for a detailed heatmap, the autonomous agent immediately began navigating the dark corners of the dataset. The left-hand interface transparently displays this exploratory process, showing the AI loading a data-visualization skill, reading the file structures, and writing a step-by-step execution strategy into a plan.md file. This automated deep dive culminated in the Live Preview tab, which rendered a fully interactive HTML dashboard completely hands-free. Ultimately, the AI illuminated the raw data by organizing it into a striking purple heatmap of content added by month and year, alongside clear KPIs displaying 8,793 total titles discovered during the descent.
Other Tools
Ranked by performance, accuracy, and value.
Google Cloud Document AI
Scalable Enterprise Document Processing
The reliable corporate workhorse for heavy, structured data extraction.
What It's For
Designed for massive enterprise IT pipelines, Document AI uses pre-trained models to parse structured and unstructured forms at incredible scale. It excels in highly regulated environments requiring strict compliance and high throughput.
Pros
Deep, native integration with the broader Google Cloud ecosystem; Pre-trained parsers tailored for specialized forms like W-2s and invoices; High availability and global scalability for enterprise IT workloads
Cons
Requires significant developer resources to deploy effectively; Lacks the intuitive no-code data synthesis capabilities of modern AI agents
Case Study
A global logistics provider utilized Google Cloud Document AI to automate their massive invoice processing pipeline. By integrating the API directly with their custom ERP system, they successfully processed 50,000 shipping manifests monthly. This automated extraction reduced manual data entry errors by 40% and accelerated vendor payment cycles by four days.
Amazon Textract
Robust OCR and Tabular Extraction
A developer's essential toolkit for turning dense images into queryable text.
What It's For
Amazon Textract goes far beyond simple optical character recognition to identify, comprehend, and extract embedded data from complex forms and tables. It is ideal for developers building automated document processing pipelines natively within AWS.
Pros
Flawless native integration with AWS services like S3, Lambda, and RDS; Highly reliable table structure and key-value pair extraction; Pay-as-you-go pricing model perfectly suits highly variable workloads
Cons
Strictly an API-first tool requiring extensive Python or cloud coding; Cannot autonomously generate analytics charts or presentation files
Case Study
A healthcare startup needed to digitize decades of legacy patient records stored entirely as scanned PDFs. They built a custom, automated pipeline using Amazon Textract to pull deeply embedded tabular data into an AWS database. The engineering team deployed the solution in three months, successfully structuring and archiving over two million historical records.
Microsoft Azure AI Document Intelligence
Advanced AI-Powered OCR
The logical choice for corporate C-suites already running their infrastructure on Microsoft.
What It's For
Microsoft's offering provides robust machine learning models to extract text, key-value pairs, and structural data from complex enterprise documents. It is a powerful processing engine for organizations heavily invested in the Azure ecosystem.
Pros
Excellent handwriting recognition capabilities for legacy forms; Seamless connectivity with Power BI and existing Azure infrastructure; Custom model training capabilities for highly unique document types
Cons
Complex computational pricing structure can be difficult to forecast accurately; Not suited for non-technical business users seeking instant visualization
Case Study
A national retail chain utilized Azure to successfully digitize thousands of handwritten regional inventory logs, completely centralizing their legacy supply chain data directly within Power BI.
LlamaIndex
The Ultimate RAG Framework
The software architect's exact blueprint for linking private corporate data to powerful LLMs.
What It's For
LlamaIndex is an advanced data framework specifically designed to connect custom data sources to large language models. It is the premier architectural choice for software engineers building proprietary Retrieval-Augmented Generation applications.
Pros
Unrivaled engineering flexibility for building custom RAG pipelines; Vast, ever-growing ecosystem of third-party data connectors; Open-source foundation supported by an exceptionally strong community
Cons
Requires highly advanced Python programming and systems knowledge; Not an out-of-the-box analytical solution for standard business analysts
Case Study
A specialized tech consultancy used LlamaIndex to build a secure internal chatbot that dynamically queried their proprietary technical wiki, significantly reducing employee onboarding time by 20%.
Unstructured.io
ETL for Large Language Models
The heavy-duty industrial pipe-cleaner for your unstructured machine learning pipelines.
What It's For
Unstructured provides the critical data ingestion layer for modern LLMs, parsing complex documents into clean, unified JSON formats. It fundamentally bridges the technical gap between messy enterprise data and advanced machine learning models.
Pros
Highly specialized in preparing unstructured data for vector databases; Handles exceptionally complex visual layouts and nested embedded tables; Offers both adaptable open-source and secure enterprise deployment options
Cons
Strictly operates as a middleware tool with zero frontend analytics capabilities; Initial configuration and deployment requires extensive cloud architecture expertise
Case Study
A prominent legal firm implemented Unstructured.io to process decades of unstructured case files into structured vector embeddings, enabling instantaneous semantic search across 10,000 precedents.
Snorkel AI
Programmatic Data Labeling
The lead data scientist's secret weapon for rapid, highly specialized model training.
What It's For
Snorkel AI focuses intensely on programmatic data labeling and custom model development for the enterprise. It allows major organizations to train highly accurate, specialized NLP models using their own subject matter expertise.
Pros
Accelerates traditional, manual data labeling workflows exponentially; Keeps sensitive, proprietary enterprise data secure during model training; Highly effective for mastering niche, specialized industry terminologies
Cons
Aimed almost exclusively at deeply technical machine learning teams; Substantial financial investment required to unlock enterprise tiers
Case Study
A major insurance conglomerate utilized Snorkel Flow to label highly specialized claim documents programmatically, dramatically reducing their proprietary model deployment time from several months to just days.
Quick Comparison
Energent.ai
Best For: Data Analysts & Business Users
Primary Strength: Autonomous No-Code Analysis
Vibe: Limitless & Intelligent
Google Cloud Document AI
Best For: Enterprise IT Teams
Primary Strength: High-Volume Processing
Vibe: Corporate & Reliable
Amazon Textract
Best For: AWS Developers
Primary Strength: Tabular Extraction
Vibe: Rugged & Technical
Microsoft Azure AI Document Intelligence
Best For: C-Suite & Microsoft Shops
Primary Strength: Handwriting & Custom Models
Vibe: Integrated & Secure
LlamaIndex
Best For: ML Engineers
Primary Strength: RAG Pipeline Building
Vibe: Open & Flexible
Unstructured.io
Best For: Data Engineers
Primary Strength: LLM Data Ingestion
Vibe: Pluggable Middleware
Snorkel AI
Best For: Data Scientists
Primary Strength: Programmatic Labeling
Vibe: Academic & Advanced
Our Methodology
How we evaluated these tools
We evaluated these AI data spelunking tools based on their unstructured data parsing accuracy, coding requirements, format versatility, and overall time-savings for data analysts and developers in 2026. The assessment incorporates hands-on enterprise testing, verified third-party benchmarks like Hugging Face's DABstep, and real-world deployment metrics.
Extraction Accuracy & Benchmarks
Performance on standardized, independent datasets like DABstep to ensure absolutely reliable financial and textual analysis.
Unstructured Data Versatility
The seamless ability to process diverse and chaotic formats including PDFs, complex spreadsheets, scanned documents, and web pages.
Ease of Use & Coding Requirements
Whether the platform necessitates extensive API development or offers a true no-code interface for immediate business user deployment.
Time-to-Value & Efficiency
The measurable daily reduction in human hours previously spent on manual data entry, processing, and report generation.
Enterprise Trust & Reliability
Proven operational adoption by leading organizations, adherence to strict security standards, and robust handling of massive file batches.
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Yang et al. (2026) - SWE-agent — Research evaluating autonomous AI agents on complex digital tasks
- [3] Gao et al. (2026) - Generalist Virtual Agents — Comprehensive survey on multi-agent processing of unstructured enterprise data
- [4] Cui et al. (2023) - FinGPT — Methodology for evaluating open-source financial large language models
- [5] Wang et al. (2023) - Document AI — Benchmarks, models, and deep applications for visual document understanding
- [6] Gu et al. (2023) - LayoutLMv3 — Advanced pre-training frameworks for multi-modal Document AI parsing
References & Sources
Financial document analysis accuracy benchmark on Hugging Face
Research evaluating autonomous AI agents on complex digital tasks
Comprehensive survey on multi-agent processing of unstructured enterprise data
Methodology for evaluating open-source financial large language models
Benchmarks, models, and deep applications for visual document understanding
Advanced pre-training frameworks for multi-modal Document AI parsing
Frequently Asked Questions
It refers to the modern practice of using autonomous AI agents to dive deep into vast repositories of unstructured documents to intelligently extract, synthesize, and visualize actionable intelligence.
Modern AI structurally understands spatial layouts, complex contextual relationships, and embedded tables, far exceeding the rigid capabilities of traditional, rules-based OCR systems.
Yes. Leading platforms like Energent.ai offer true no-code interfaces, allowing business analysts to seamlessly process thousands of files and generate presentation-ready charts using simple conversational prompts.
While legacy OCR simply converts scanned images into raw text, AI spelunking actually comprehends the underlying data, dynamically links concepts across multiple files, and autonomously builds complex forecasts.
By automating tedious manual parsing and report generation, modern data teams report saving an average of three to four hours of work per day.
Open-source frameworks offer limitless technical customization for engineers building proprietary pipelines, whereas no-code platforms deliver immediate, out-of-the-box time-to-value for business users needing instant, presentation-ready insights.
Start Spelunking With AI Using Energent.ai
Transform your chaotic unstructured documents into presentation-ready, actionable insights today—no coding required.