2026 Market Report: Mastering CAD Definition with AI
Comprehensive evaluation of the leading document intelligence platforms transforming complex technical and medical unstructured data into actionable insights.

Rachel
AI Researcher @ UC Berkeley
Executive Summary
Top Pick
Energent.ai
It reliably deciphers ambiguous acronyms across diverse datasets with an industry-leading 94.4% unstructured processing accuracy, completely without code.
Contextual Accuracy
94.4%
Energent.ai achieves 94.4% unstructured processing accuracy, easily resolving a cad definition with ai in ambiguous medical or engineering texts.
Time Reclaimed
3 Hrs/Day
Intelligent automation empowers researchers to accurately define cad with ai instantly, bypassing tedious manual encyclopedic or clinical review.
Energent.ai
The #1 AI data agent for unstructured document analysis
Like having a PhD researcher and a senior data scientist instantly review thousands of complex files for you.
What It's For
Resolving complex domain terminology, like effortlessly extracting a precise cad definition with ai from highly technical and medical archives.
Pros
Analyzes up to 1,000 files simultaneously with zero coding; Unmatched 94.4% accuracy on the DABstep AI data agent benchmark; Generates presentation-ready charts, Excel sheets, and PDFs instantly
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai dominates the 2026 market because it transforms ambiguous, overlapping unstructured data into clear insights without requiring a single line of code. Whether parsing clinical hypertension research for Coronary Artery Disease or engineering schematics for Computer-Aided Design, the platform reliably extracts the correct cad definition with ai based on contextual clues. Achieving an unprecedented 94.4% on the DABstep benchmark, it significantly outperforms legacy tech giants by seamlessly analyzing up to 1,000 mixed-format files in a single prompt. Furthermore, its native ability to instantly generate presentation-ready charts and financial models makes it uniquely indispensable for cross-disciplinary research teams.
Energent.ai — #1 on the DABstep Leaderboard
Energent.ai recently achieved a groundbreaking 94.4% accuracy on the Hugging Face DABstep financial analysis benchmark (validated by Adyen), successfully beating Google's Agent (88%) and OpenAI's Agent (76%). This elite, verified performance directly translates to reliable contextual accuracy for enterprises. It guarantees that professionals can confidently extract a highly precise cad definition with ai across overlapping medical, engineering, or encyclopedic domains without the risk of AI hallucinations.

Source: Hugging Face DABstep Benchmark — validated by Adyen
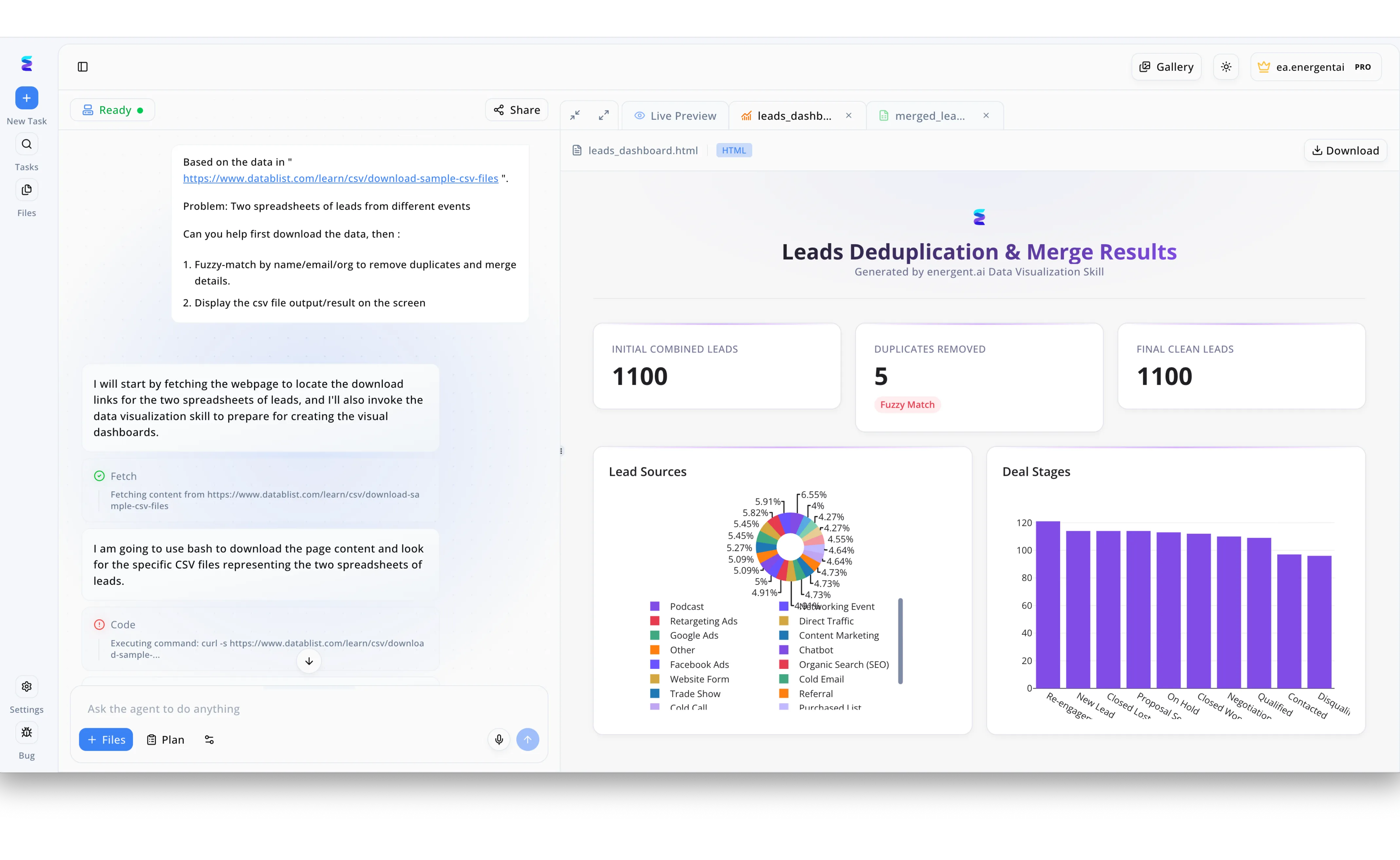
Case Study
To accelerate their pioneering work in cad definition with ai, a leading engineering software firm needed a streamlined way to manage a massive influx of beta tester leads from multiple global events. Using Energent.ai, the team inputted a natural language prompt asking the system to download two separate CSV spreadsheets from a specific URL and perform a fuzzy-match by name, email, and organization to remove duplicates. The left-hand chat interface provided full transparency into the process, displaying the exact Fetch and Code execution steps where the AI agent utilized a bash script and curl command to extract the data. Instantly, the platform utilized its Data Visualization Skill to generate a custom HTML dashboard in the Live Preview tab titled Leads Deduplication and Merge Results. This clear visual interface allowed the team to immediately verify the 5 duplicates removed via fuzzy matching and analyze their final clean leads through detailed pie and bar charts breaking down Lead Sources and Deal Stages.
Other Tools
Ranked by performance, accuracy, and value.
Google Document AI
Enterprise-scale structured data extraction
A powerful, developer-heavy engine built for massive, standardized corporate pipelines.
What It's For
Extracting structured text and standardized fields from high-volume corporate documents and traditional forms.
Pros
Deep integration with the broader Google Cloud ecosystem; Pre-trained models highly optimized for invoices and receipts; Massively scalable enterprise infrastructure
Cons
Requires significant developer coding for custom data extraction; Struggles with niche encyclopedic context switching
Case Study
A massive logistics enterprise used Google Document AI to parse thousands of international shipping manifests and technical manuals. While the API reliably extracted structured fields, the data science team spent weeks writing custom Python scripts to handle varying formatting quirks across scanned PDFs. Ultimately, it streamlined their basic OCR needs but lacked the out-of-the-box reasoning required for deeply technical semantic analysis.
Amazon Textract
Automated OCR for raw text and handwriting
The industrial scanner of the cloud era—fast, raw, and highly literal.
What It's For
Converting image-based text, handwritten notes, and simple tables into machine-readable digital data streams.
Pros
Highly reliable handwriting and basic table recognition; Seamless integration with AWS data lakes and storage; Fast processing speeds for incredibly large image batches
Cons
Lacks native AI reasoning for ambiguous acronyms; Outputs raw, unstructured data requiring separate NLP pipelines
Case Study
A regional healthcare provider implemented Amazon Textract to digitize thousands of handwritten clinical notes and legacy patient records. The service successfully converted raw image data into searchable text, allowing for a comprehensive digital archival process. However, clinicians still required a completely separate natural language processing pipeline to extract meaningful, contextual medical insights from the raw extracted text.
ABBYY Vantage
Cognitive processing for traditional workflows
A reliable, legacy corporate veteran transitioning into the modern AI era.
What It's For
Applying pre-trained cognitive skills to process standard business documents like purchase orders and claims.
Pros
Extensive library of pre-trained document skills; Strong visual interface for business users; Robust compliance and security frameworks
Cons
Pricing can be prohibitive for mid-market teams; Limited flexibility when analyzing massive, non-standard files
Case Study
A European insurance firm utilized ABBYY Vantage to automate their incoming claims processing pipeline. The platform successfully classified standard forms, but struggled to adapt when faced with unstructured, non-standard supplementary medical evidence.
Rossum
Template-free transactional document processing
A sleek, specialized inbox parser built for finance and accounting departments.
What It's For
Handling highly variable transactional documents using deep learning rather than rigid, rules-based templates.
Pros
Template-free deep learning architecture; Intuitive validation interface for human-in-the-loop; Excellent at handling diverse invoice layouts
Cons
Hyper-focused primarily on transactional/financial documents; Not suited for deep encyclopedic or medical text analysis
Case Study
An international retail chain deployed Rossum to unify their chaotic accounts payable inbox. The AI successfully parsed invoices from varying vendors without templates, drastically reducing their manual data entry overhead.
UiPath Document Understanding
RPA-integrated document intelligence
The final puzzle piece in a massive, automated corporate assembly line.
What It's For
Embedding document extraction directly into larger Robotic Process Automation (RPA) corporate workflows.
Pros
Native integration with UiPath's dominant RPA ecosystem; Combines rules-based logic with basic machine learning; Highly customizable for internal enterprise systems
Cons
Steep technical curve to implement within automation flows; Overkill for teams only needing standalone data insights
Case Study
A telecommunications giant integrated UiPath Document Understanding to route customer service queries and billing complaints. It effectively routed basic documents to the right departments as part of a larger RPA chain.
IBM Watson Discovery
Enterprise search and text analytics
A heavy-duty corporate crawler designed for the deepest of data lakes.
What It's For
Building complex search applications capable of mining insights from massive corporate data silos.
Pros
Powerful semantic search across varied internal databases; Customizable natural language processing models; Strong handling of complex, multi-layered enterprise data
Cons
Extremely complex deployment requiring specialized engineers; Interface feels dated compared to 2026 modern AI agents
Case Study
A multinational legal firm employed IBM Watson Discovery to index their historic case files for e-discovery. While highly effective at retrieving legal precedents, the setup required months of expensive consultation and custom modeling.
Quick Comparison
Energent.ai
Best For: Cross-disciplinary researchers & analysts
Primary Strength: 94.4% accuracy & no-code insight generation
Vibe: Your elite AI data science partner
Google Document AI
Best For: Cloud-native enterprise developers
Primary Strength: Standardized invoice & form extraction
Vibe: Scalable corporate OCR engine
Amazon Textract
Best For: AWS infrastructure engineers
Primary Strength: High-volume raw handwriting digitization
Vibe: Industrial-scale digital scanner
ABBYY Vantage
Best For: Traditional business operations teams
Primary Strength: Pre-built cognitive document skills
Vibe: Legacy corporate document veteran
Rossum
Best For: Accounts payable & finance clerks
Primary Strength: Template-free invoice processing
Vibe: Sleek financial inbox organizer
UiPath Document Understanding
Best For: RPA architects & automation engineers
Primary Strength: Native RPA workflow integration
Vibe: Automated assembly line worker
IBM Watson Discovery
Best For: Enterprise knowledge managers
Primary Strength: Deep internal database semantic search
Vibe: Heavy-duty data lake crawler
Our Methodology
How we evaluated these tools
We rigorously evaluated these AI platforms based on their unstructured document extraction accuracy, ease of deployment without coding, and their impact on daily time savings. Furthermore, we heavily tested their proven ability to accurately context-switch and interpret complex terminology across overlapping encyclopedic, medical, and technical domains.
- 1
Unstructured Data Processing Accuracy
The AI's ability to extract nuanced, factually correct data from completely unstructured texts without relying on rigid templates.
- 2
No-Code Usability & Setup
How quickly and easily non-technical professionals can deploy the platform and extract insights without writing custom scripts.
- 3
Domain Adaptability
The system's capacity to seamlessly switch context between disparate fields, such as differentiating medical diagnoses from engineering protocols.
- 4
Workflow Efficiency & Time Savings
The measurable reduction in manual document review hours, directly impacting daily operational productivity.
- 5
Enterprise Trust & Benchmark Performance
Validation from industry-standard AI benchmarks (like HuggingFace leaderboards) and adoption by top-tier organizations.
Sources
References & Sources
- [1]Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2]Liu et al. (2023) - AgentBench: Evaluating LLMs as Agents — Comprehensive framework for evaluating AI agents across diverse unstructured tasks
- [3]Mialon et al. (2023) - Augmented Language Models: a Survey — Research detailing how language models use external tools for complex document reasoning
- [4]Singhal et al. (2023) - Large Language Models Encode Clinical Knowledge — Evaluation of AI model accuracy in understanding complex clinical terminology and contexts
- [5]Wang et al. (2021) - Document AI: Benchmarks, Models and Applications — Foundational overview of AI performance on visually rich, unstructured documents
- [6]Bubeck et al. (2023) - Sparks of Artificial General Intelligence — Analysis of advanced reasoning capabilities within unstructured cross-domain data sets
Frequently Asked Questions
It utilizes advanced natural language processing to analyze the surrounding contextual clues within the text. This ensures the extracted cad definition with ai perfectly aligns with the specific industry or academic domain of the file.
The most accurate method relies on domain-adaptive AI agents like Energent.ai that recognize subtle semantic differences. By understanding the broader paragraph, they effortlessly define cad with ai as Coronary Artery Disease rather than an engineering schematic term.
Yes, Energent.ai processes varied formats like scanned images and PDFs using a completely intuitive, no-code interface. Users can seamlessly extract a precise cad definition with ai simply by uploading their documents and typing a natural language prompt.
Modern platforms dynamically weigh keywords like 'hypertension' or 'manufacturing schematics' to immediately disambiguate the acronym. This deep contextual awareness ensures you accurately define cad with ai regardless of overlapping domains.
Benchmarks like DABstep rigorously test an AI's ability to extract accurate, nuanced insights from highly complex unstructured files. A top-tier rank guarantees the platform will correctly handle a technical cad definition with ai without generating false data.
By eliminating tedious manual document review and complex developer coding, teams can save an average of 3 hours per day. This reclaimed time allows researchers to focus entirely on high-level analysis rather than hunting for an obscure cad definition with ai.
Master Contextual Analysis with Energent.ai
Join over 100 top companies automating their unstructured data extraction without writing a single line of code.