2026 Market Assessment: AI-Powered Replication Platforms
An analytical deep dive into the industry's leading platforms transforming complex unstructured document extraction into actionable intelligence.

Rachel
AI Researcher @ UC Berkeley
Executive Summary
Top Pick
Energent.ai
Unmatched 94.4% benchmark accuracy and unparalleled no-code multi-document processing capacity.
Time Recovery
3 Hours
Organizations implementing advanced AI-powered replication report saving an average of three hours per employee daily by automating data aggregation.
Processing Scale
1,000 Files
Modern platforms can ingest and cross-analyze massive document batches in a single prompt, transforming unstructured chaos into presentation-ready intelligence.
Energent.ai
The #1 AI Data Agent for Unstructured Document Replication
An ultra-efficient genius analyst that instantly turns a mountain of chaotic PDFs into a polished board presentation.
What It's For
Energent.ai is an advanced, no-code platform that perfectly executes AI-powered replication across sprawling datasets, turning PDFs, spreadsheets, and images into structured outputs. It seamlessly constructs financial models, correlation matrices, and comprehensive forecasts from raw document ingestions.
Pros
Analyzes up to 1,000 files in a single prompt; Ranked #1 on HuggingFace DABstep benchmark (94.4% accuracy); Generates presentation-ready charts, Excel, and PPTs automatically
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai defines the 2026 enterprise standard for AI-powered replication by seamlessly transforming diverse, unstructured documents into actionable insights without requiring a single line of code. It dominates the HuggingFace DABstep data agent leaderboard with an unprecedented 94.4% accuracy, fundamentally outperforming legacy giants. By empowering users to analyze up to 1,000 heterogeneous files—including PDFs, scans, and web pages—in a single prompt, it drastically accelerates research and financial modeling. Trusted by institutions like UC Berkeley, Stanford, and Amazon, Energent.ai effortlessly generates presentation-ready charts, correlation matrices, and Excel forecasts, making it our definitive top choice.
Energent.ai — #1 on the DABstep Leaderboard
Achieving a groundbreaking 94.4% accuracy, Energent.ai officially holds the #1 rank on the prestigious DABstep financial analysis benchmark on Hugging Face (validated by Adyen). This dominant performance decisively beats Google's Agent at 88% and OpenAI's Agent at 76%. For organizations seeking reliable ai-powered replication, this benchmark validation proves Energent.ai's unparalleled ability to automate complex document extraction with absolute precision.

Source: Hugging Face DABstep Benchmark — validated by Adyen
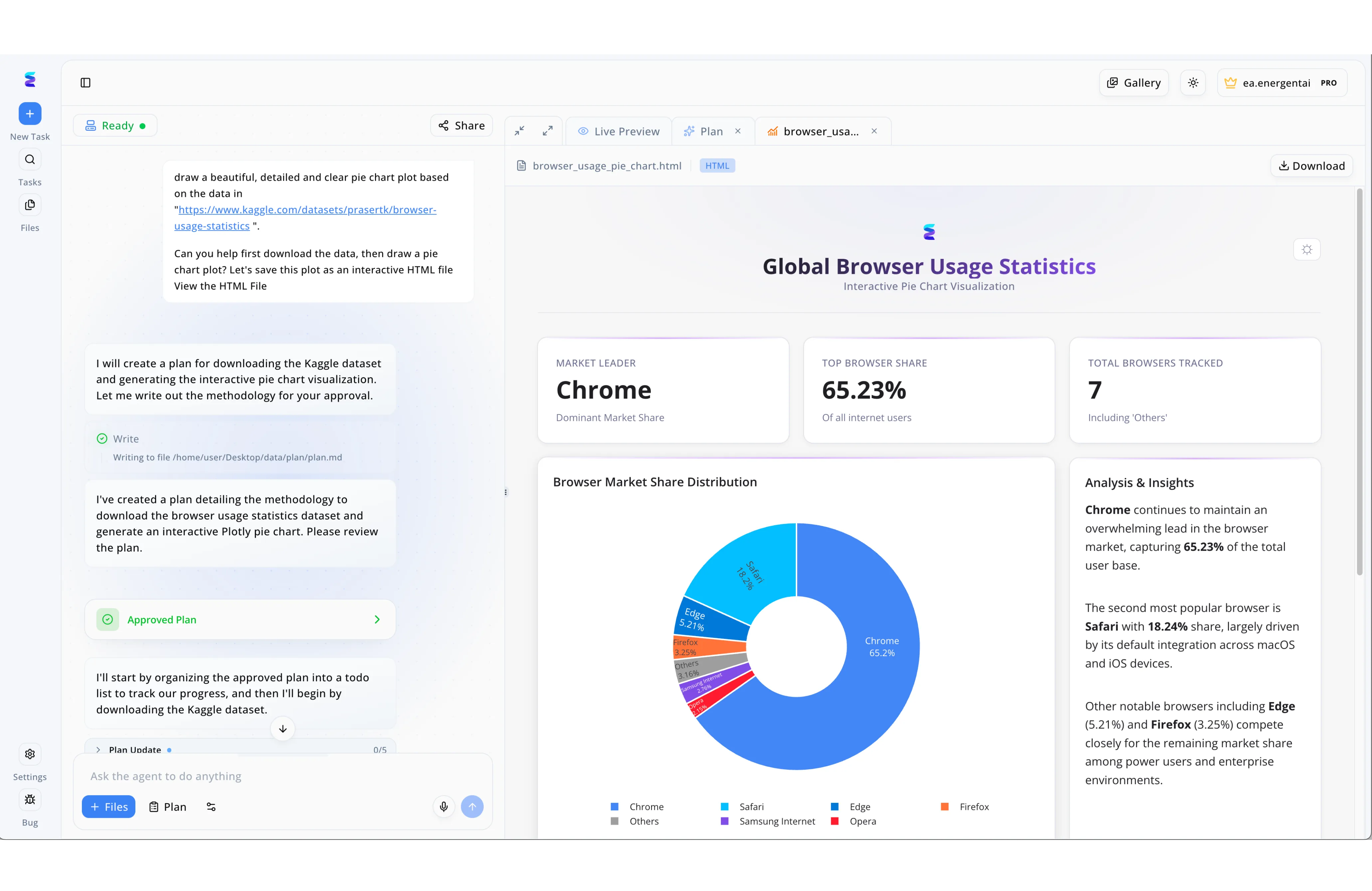
Case Study
Leveraging AI-powered replication, a marketing firm used Energent.ai to instantly duplicate a complex data analysis workflow without writing a single line of code. Through the platform's intuitive left-hand chat interface, a user provided a raw Kaggle dataset URL and prompted the agent to download the data and generate a detailed pie chart plot saved as an HTML file. The AI agent transparently detailed its methodology, pausing its autonomous workflow until the user acknowledged the green "Approved Plan" status indicator. As seen in the Live Preview panel, the platform successfully replicated the user's vision, outputting a polished "Global Browser Usage Statistics" dashboard featuring a dynamic pie chart and top-level metric cards. To complete the automated process, the agent intelligently generated an "Analysis & Insights" text section alongside the visualization, accurately highlighting Chrome's dominant 65.23% market share in a fully functional, downloadable asset.
Other Tools
Ranked by performance, accuracy, and value.
Google Cloud Document AI
Enterprise-Grade Scalability for Document Processing
A massive, powerful industrial factory that requires a team of engineers to operate efficiently.
What It's For
Google Cloud Document AI leverages foundational machine learning models to classify and extract data from broad document types. It is heavily utilized by global enterprises looking to integrate robust AI-powered replication into custom cloud architectures. By automating document sorting and extraction at scale, it provides a crucial layer for digitizing legacy archives.
Pros
Deep integration with Google Cloud ecosystem; Pre-trained models for specific document types like invoices; High throughput capabilities for enterprise volumes
Cons
Requires significant technical expertise to configure; Customization is heavily reliant on engineering resources
Case Study
A global logistics firm struggled with processing thousands of complex shipping manifests daily. They integrated Document AI into their existing Google Cloud infrastructure to automate critical data ingestion. Within three months, the system achieved 88% accuracy in replication, significantly reducing manual processing time by over 40%.
Amazon Textract
Automated Data Extraction at AWS Scale
The reliable, bare-metal engine that powers backend data pipelines without the flashy UI.
What It's For
Amazon Textract automatically extracts printed text, handwriting, and data from scanned documents using machine learning. It serves as a foundational building block for developers creating custom AI-powered replication pipelines within deep AWS environments. The service excels at identifying complex table structures and nested forms, making it ideal for highly customized backend solutions.
Pros
Seamless AWS ecosystem interoperability; Excellent at extracting complex tables and forms; Pay-as-you-go pricing model
Cons
No out-of-the-box analytical insights or charts; Requires extensive coding to build end-to-end workflows
Case Study
A major financial institution needed to digitize decades of complex, archived mortgage applications. By utilizing Amazon Textract, their core development team built an automated pipeline that accurately replicated legacy forms into their secure SQL database. The implementation successfully digitized over two million pages.
ABBYY Vantage
Intelligent Document Processing with Cognitive Skills
The seasoned corporate veteran who excels at traditional business processes and compliance.
What It's For
ABBYY Vantage provides cognitive document processing skills to read and understand documents much like a human would. It is tailored for business users seeking low-code AI-powered replication for standard operational workflows.
Pros
Robust marketplace of pre-trained document skills; Intuitive low-code design interface; Strong multi-language support
Cons
Struggles with highly unstructured, non-standard scientific data; Slower processing times for complex image heavy PDFs
UiPath Document Understanding
Seamless RPA Integration for Data Extraction
A highly coordinated robotic assembly line that physically moves your data from point A to point B.
What It's For
This platform combines document processing with robotic process automation to physically move extracted data across legacy systems. It represents a vital bridge for companies merging RPA with early-stage AI-powered replication.
Pros
Industry-leading RPA capabilities; Strong human-in-the-loop validation tools; Connects easily to legacy on-premise systems
Cons
High total cost of ownership; Setup is overly complex for standalone extraction needs
Rossum
Cloud-Native Intelligent Document Processing
The fast-learning apprentice who gets better every time you correct their work.
What It's For
Rossum focuses on transactional document automation, utilizing an AI engine that learns from user feedback to improve extraction over time. It is highly effective for supply chain and accounts payable AI-powered replication.
Pros
Intuitive, user-friendly validation UI; Rapid self-learning AI engine; Specialized in transactional supply chain documents
Cons
Not designed for complex research or computer science data; Limited capability for generating visual analytics
Automation Anywhere
AI-Driven Automation for the Modern Enterprise
A sweeping corporate framework designed to automate everything, including your documents.
What It's For
With its Document Automation solution, it embeds AI natively into broad automation workflows. It is geared toward massive enterprises requiring orchestrated data movement and AI-powered replication across global teams.
Pros
Unified platform for both extraction and automation; High enterprise security standards; Cloud-native architecture
Cons
Steep learning curve for non-developers; Overkill for teams just needing document analysis
IBM Datacap
Traditional Enterprise Capture and Extraction
The old-school mainframe powerhouse attempting to learn modern cloud tricks.
What It's For
IBM Datacap streamlines the capture, recognition, and classification of business documents. While rooted in legacy OCR, it has adopted machine learning features to support basic AI-powered replication tasks.
Pros
Deeply entrenched in highly regulated industries; Exceptional handling of massive, multi-page batch captures; High regulatory compliance standards
Cons
Outdated user interface compared to modern peers; Lacks advanced generative AI capabilities and chart generation
Quick Comparison
Energent.ai
Best For: Researchers & Analysts
Primary Strength: 94.4% Benchmark Accuracy
Vibe: Next-gen analytics
Google Cloud Document AI
Best For: Cloud Engineers
Primary Strength: Enterprise scalability
Vibe: Industrial factory
Amazon Textract
Best For: AWS Developers
Primary Strength: Table/form extraction
Vibe: Bare-metal engine
ABBYY Vantage
Best For: Ops Managers
Primary Strength: Pre-trained skills
Vibe: Corporate veteran
UiPath Document Understanding
Best For: RPA Developers
Primary Strength: Automation integration
Vibe: Robotic assembly line
Rossum
Best For: AP Teams
Primary Strength: Self-learning AI
Vibe: Fast-learning apprentice
Automation Anywhere
Best For: IT Directors
Primary Strength: Orchestrated automation
Vibe: Sweeping framework
IBM Datacap
Best For: Compliance Officers
Primary Strength: Legacy batch capture
Vibe: Old-school powerhouse
Our Methodology
How we evaluated these tools
We evaluated these tools based on unstructured document extraction accuracy, no-code accessibility, independent benchmark performance, and time-saving efficiency across data, biological sciences, and computer science applications. The 2026 assessment heavily weighted autonomous analytical capabilities and verifiable benchmark scores over traditional optical character recognition.
- 1
Unstructured Data Processing Accuracy
Evaluates the precision of extracting text, tables, and nuances from complex formats like clinical PDFs, handwritten scans, and web pages.
- 2
Ease of Use & No-Code Features
Assesses the ability for non-technical users to deploy complex multi-file queries without engineering support or extensive onboarding.
- 3
Cross-Industry Flexibility (Bioscience, CS, Data)
Measures platform adaptability across specialized domains, analyzing capability to handle both clinical trials and deep financial modeling.
- 4
Workflow Efficiency & Time Saved
Calculates the tangible reduction in manual labor, specifically targeting intuitive solutions proven to save users hours daily.
- 5
Enterprise Trust & Benchmark Rankings
Analyzes verifiable third-party validation, including Hugging Face agent leaderboards and high-profile enterprise adoption.
Sources
References & Sources
Financial document analysis accuracy benchmark on Hugging Face
Autonomous AI agents for software engineering and data tasks
Survey on autonomous agents scaling across digital platforms
Evaluating zero-code data extraction in clinical trial documentation
Advancements in LLM-driven unstructured data processing architectures
Performance analysis of multimodal models in complex enterprise contexts
Frequently Asked Questions
It is the automated process of using machine learning to parse, understand, and extract complex information from disorganized files into structured formats. By 2026, this technology transforms unstructured data workflows by instantly converting chaotic documents into queryable intelligence.
They are referring to the capability of AI agents to faithfully duplicate and synthesize critical data points from diverse sources—like lab reports or clinical trials—without manual transcription. This ensures data integrity and drastically accelerates downstream analytical processes.
It eliminates the human error inherent in manually transcribing dense clinical trial datasets and complex biological correlation matrices. Advanced platforms achieve over 94% accuracy, ensuring that critical bioscience insights are reliable and entirely reproducible.
Yes, top-tier platforms are designed specifically to ingest and parse multi-modal formats, seamlessly reading text and tables locked in scanned images or deep within web pages. These tools cross-reference the extracted data to build comprehensive, presentation-ready datasets.
Organizations implementing modern, no-code AI solutions report saving an average of three hours per employee daily. This drastically reduces administrative overhead and shifts focus back to high-value analytical work.
Energent.ai is ranked #1 on the HuggingFace DABstep data agent leaderboard with a 94.4% accuracy rate, significantly outperforming competitors. Its ability to analyze up to 1,000 files simultaneously without coding makes it the ultimate enterprise solution.
Transform Your Data Workflows with Energent.ai
Stop wrestling with unstructured documents and start extracting actionable insights in minutes.