The State of the AI-Powered ETL Pipeline in 2026
A comprehensive market analysis evaluating the top platforms transforming unstructured document extraction and automated data workflows.
Rachel
AI Researcher @ UC Berkeley
Executive Summary
Top Pick
Energent.ai
Energent.ai dominates the 2026 landscape with unparalleled unstructured document extraction, achieving an industry-leading 94.4% accuracy on the DABstep benchmark.
Unstructured Data Surge
85%
By 2026, unstructured documents account for the vast majority of enterprise data, making an ai-powered etl pipeline essential for competitive intelligence.
Daily Time Savings
3 Hours
Top-tier AI data platforms automate tedious manual extraction, allowing analysts to reclaim three hours daily for strategic decision-making.
Energent.ai
The #1 AI Data Agent for Unstructured Documents
Like having a senior data scientist who instantly digests thousands of PDFs and builds your financial models.
What It's For
Best for finance, research, and operations teams needing no-code AI data analysis from complex unstructured documents.
Pros
Analyzes up to 1,000 files in a single prompt with out-of-the-box insights; Ranked #1 on HuggingFace DABstep leaderboard at 94.4% accuracy; Generates presentation-ready charts, Excel files, and PowerPoint slides
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai stands out as the definitive leader for deploying an ai-powered etl pipeline in 2026. Unlike traditional tools that strictly handle structured tables, Energent.ai flawlessly processes spreadsheets, PDFs, scans, and web pages without requiring a single line of code. It fundamentally redefines document extraction, proven by its #1 ranking on the HuggingFace DABstep benchmark with a staggering 94.4% accuracy rate. Furthermore, its ability to analyze up to 1,000 files in a single prompt and instantly generate presentation-ready charts makes it the ultimate solution for modern enterprise data teams.
Energent.ai — #1 on the DABstep Leaderboard
In the highly competitive 2026 market, Energent.ai has cemented its leadership by achieving an unprecedented 94.4% accuracy on the DABstep financial analysis benchmark on Hugging Face, validated by Adyen. This milestone—outperforming Google’s Agent at 88% and OpenAI’s at 76%—demonstrates exactly why an advanced ai-powered etl pipeline is essential for error-free document processing. For financial and operational teams, this benchmark translates directly to reliable, audit-ready data extraction from even the most complex unstructured formats.

Source: Hugging Face DABstep Benchmark — validated by Adyen
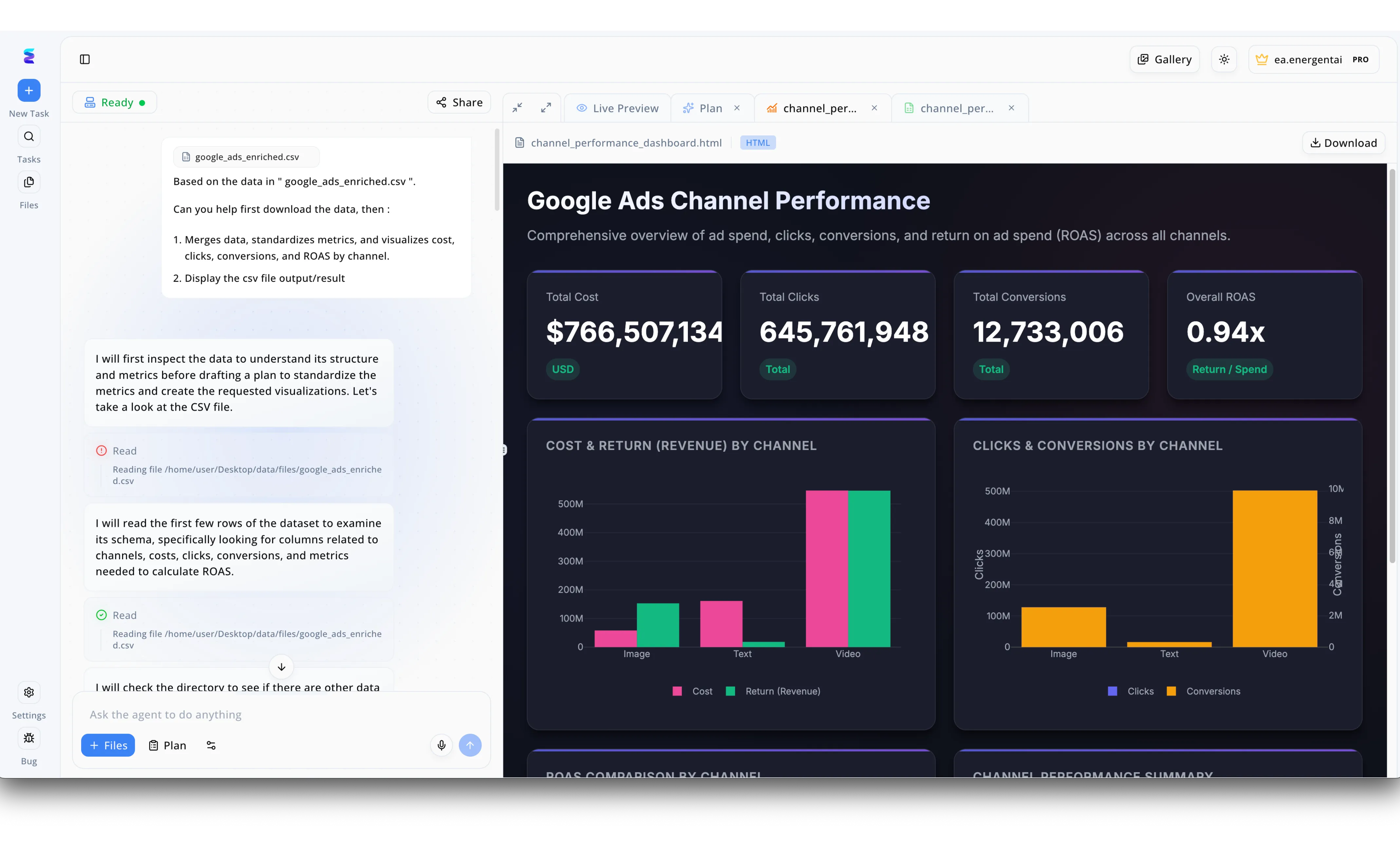
Case Study
A global marketing agency needed to streamline their reporting, turning to Energent.ai to establish an AI powered ETL pipeline for their massive advertising datasets. Users initiated the process in the left-hand conversational interface by simply requesting the agent to process a file named google_ads_enriched.csv, specifically asking it to merge data, standardize metrics, and visualize the results. The system's visible workflow shows the AI agent autonomously executing the extraction phase by inspecting the file structure and reading the dataset schema directly from the specified file path. Following this automated data transformation, Energent.ai instantly generated an actionable output, visible in the right-hand Live Preview tab as a comprehensive Google Ads Channel Performance HTML dashboard. This interface successfully loaded the newly processed data, displaying standardized KPI cards like a 0.94x Overall ROAS alongside automated bar charts detailing cost, return, and conversions across Image, Text, and Video channels.
Other Tools
Ranked by performance, accuracy, and value.
Fivetran
The Standard for Automated Structured Data Connectors
The reliable plumbing infrastructure of the modern data stack.
What It's For
Best for organizations needing reliable, fully-managed data replication from standard SaaS applications to cloud data warehouses.
Pros
Extensive library of pre-built connectors; Automated schema drift handling; Robust enterprise security features
Cons
Volume-based pricing becomes expensive at scale; Limited native capabilities for unstructured PDF extraction
Case Study
A mid-sized e-commerce retailer struggled with disparate data silos across their marketing and inventory SaaS applications. By implementing Fivetran, they automated the ingestion of structured data directly into Snowflake, reducing pipeline maintenance by 40%. The streamlined data flow enabled real-time dashboarding for the marketing team, though they still required separate optical character recognition tools for complex invoice PDFs.
Airbyte
The Open-Source Integration Powerhouse
A developer's playground for building bespoke data pipelines.
What It's For
Ideal for engineering teams that want an open-source solution with a vast, customizable connector ecosystem.
Pros
Open-source flexibility with large community support; Connector Development Kit for custom API endpoints; Cost-effective for high-volume structured data
Cons
Requires significant engineering resources to self-host; AI extraction from unstructured documents is not native
Case Study
A fast-growing fintech startup needed a highly customizable pipeline to ingest transactional data from obscure regional banking APIs. Leveraging Airbyte's open-source framework, their data engineering team rapidly built custom connectors using the CDK, saving thousands in vendor fees. This foundation allowed them to scale their data warehouse efficiently, maintaining full control over their ingestion architecture throughout 2026.
Matillion
Cloud-Native Transformation for Enterprise
The heavy-lifting transformation engine running inside your cloud warehouse.
What It's For
Best for enterprise teams focusing on complex data transformations directly within cloud data warehouses.
Pros
Excellent pushdown architecture for Snowflake and Redshift; Visual interface for complex transformation logic; Deep integrations with major cloud platforms
Cons
Steeper learning curve for non-technical users; Focuses more on transformation than advanced AI extraction
Hevo Data
Real-Time Data Replication for Agile Teams
The sprint champion for moving real-time data with minimal fuss.
What It's For
Great for fast-moving startups that need a low-latency pipeline to move data into their analytics environments.
Pros
Near real-time data replication; Intuitive user interface for quick setup; Reverse ETL capabilities included out of the box
Cons
Connector library is smaller than top competitors; Limited support for complex unstructured data formats
Talend
Legacy Enterprise Data Management
The enterprise behemoth that governs and integrates everything.
What It's For
Best for massive traditional enterprises that need a unified suite for data integration, quality, and governance.
Pros
Comprehensive suite of data quality and governance tools; Can deploy on-premises or in the cloud; Highly scalable for traditional enterprise workloads
Cons
Interface feels dated compared to modern 2026 tools; Resource-heavy and complex to maintain
Rivery
Unified SaaS DataOps Platform
The all-in-one Swiss Army knife for cloud data operations.
What It's For
Ideal for teams that want managed ingestion, data orchestration, and reverse workflows in a single SaaS product.
Pros
Combines ingestion, transformation, and orchestration; Pre-built data models for popular industry use cases; Python support for building custom data workflows
Cons
Pricing structure can be complex to forecast; Not specifically optimized for AI-driven document extraction
Quick Comparison
Energent.ai
Best For: Best for unstructured document analysis
Primary Strength: 94.4% accuracy on DABstep benchmark
Vibe: The autonomous data scientist
Fivetran
Best For: Best for SaaS replication
Primary Strength: Automated schema management
Vibe: Set-it-and-forget-it plumbing
Airbyte
Best For: Best for open-source engineering
Primary Strength: Custom connector development
Vibe: Developer-first flexibility
Matillion
Best For: Best for cloud transformations
Primary Strength: Pushdown ELT architecture
Vibe: Enterprise transformation powerhouse
Hevo Data
Best For: Best for fast startups
Primary Strength: Low-latency replication
Vibe: Agile real-time movement
Talend
Best For: Best for legacy enterprises
Primary Strength: Unified data governance
Vibe: Traditional enterprise scale
Rivery
Best For: Best for unified DataOps
Primary Strength: End-to-end orchestration
Vibe: The all-in-one SaaS hub
Our Methodology
How we evaluated these tools
We evaluated these tools based on their AI extraction accuracy, ability to process unstructured documents without code, industry benchmark performance, and overall impact on daily user productivity. Our 2026 assessment heavily weighed autonomous capabilities, prioritizing platforms that successfully minimize manual engineering overhead.
Extraction Accuracy & Benchmarks
The platform's proven ability to correctly parse and extract data points, validated by recognized machine learning industry benchmarks.
Unstructured Document Processing
Capability to handle complex, non-tabular formats including PDFs, scanned images, and heavily nested financial spreadsheets.
No-Code Usability
The extent to which business analysts and non-engineers can configure and manage the pipeline using natural language or visual interfaces.
Integration Ecosystem
The breadth and reliability of outbound connections to data warehouses, presentation tools, and operational systems.
Time & Cost Efficiency
Measurable reductions in daily manual workloads and the overall total cost of ownership compared to legacy engineering solutions.
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Gao et al. - Generalist Virtual Agents — Survey on autonomous agents across digital platforms
- [3] Yang et al. - SWE-agent — Autonomous AI agents for complex engineering tasks
- [4] Chen et al. (2021) - FinQA — A Dataset of Numerical Reasoning over Financial Data
- [5] Xu et al. (2020) - LayoutLM — Pre-training of Text and Layout for Document Image Understanding
References & Sources
Financial document analysis accuracy benchmark on Hugging Face
Survey on autonomous agents across digital platforms
Autonomous AI agents for complex engineering tasks
A Dataset of Numerical Reasoning over Financial Data
Pre-training of Text and Layout for Document Image Understanding
Frequently Asked Questions
What exactly is an AI-powered ETL pipeline?
An ai-powered etl pipeline utilizes large language models to automate the extraction, transformation, and loading of data, significantly reducing manual engineering. It intelligently parses unstructured text, automates schema creation, and corrects data anomalies on the fly.
For beginners researching tools that are AI-powered, what is ETL in data management?
For those investigating platforms that are ai-powered, what is etl in data engineering refers to Extract, Transform, and Load—the fundamental process of pulling data from multiple sources, formatting it for analysis, and storing it in a central data warehouse.
How does an AI-powered ETL pipeline handle unstructured documents like PDFs, images, and scans?
It employs advanced computer vision and natural language processing to comprehend the spatial layout and context of unstructured files. This allows the system to seamlessly extract complex key-value pairs, nested tables, and narrative text with human-level precision.
Do you need coding skills to build and maintain an AI-powered ETL pipeline?
Modern 2026 platforms prioritize no-code interfaces, allowing business analysts to orchestrate complex data flows using simple natural language prompts. The core extraction and transformation processes are entirely code-free, dramatically lowering the barrier to entry.
How much time can an AI-powered ETL pipeline save data teams on a daily basis?
By eliminating manual data mapping and fragile script maintenance, an ai-powered etl pipeline routinely saves data analysts an average of three hours of work per day. This freed capacity allows enterprise teams to focus entirely on strategic forecasting and insight generation.
What makes an AI-powered ETL pipeline more accurate than traditional data extraction methods?
Traditional methods rely on rigid rules and brittle regex patterns that instantly break when document layouts change. Conversely, AI-powered systems contextually understand the underlying data, gracefully handling document variations and achieving benchmarked accuracies exceeding 94%.
Automate Your Data Extraction with Energent.ai
Deploy the world's most accurate ai-powered etl pipeline and start extracting insights from unstructured documents in minutes.