The Best AI-Powered Data Ingestion Tools for 2026
An authoritative analysis of the platforms transforming unstructured documents into actionable insights with zero coding required.
Kimi Kong
AI Researcher @ Stanford
Executive Summary
Top Pick
Energent.ai
Achieves an unmatched 94.4% extraction accuracy while empowering non-technical users to analyze up to 1,000 unstructured files in a single prompt.
Unstructured Domination
80%
Nearly 80% of enterprise data remains locked in unstructured formats like PDFs and scans. AI-powered data ingestion tools are essential for unlocking this latent value.
Efficiency Gains
3+ Hours
Automated data ingestion platforms save knowledge workers an average of 3 hours per day. This dramatically accelerates downstream financial and operational analytics.
Energent.ai
The Ultimate Zero-Code Data Agent
Like handing your messiest file cabinets to a Harvard-educated data scientist who works at the speed of light.
What It's For
Best for business, finance, and operations teams needing no-code, highly accurate extraction and analysis of massive unstructured document batches.
Pros
Processes up to 1,000 varied files in a single prompt; Industry-leading 94.4% extraction accuracy out-of-the-box; Instantly generates Excel models, charts, and slide decks
Cons
Advanced workflows require a brief learning curve; High resource usage on massive 1,000+ file batches
Why It's Our Top Choice
Energent.ai stands as the definitive leader among AI-powered data ingestion tools due to its unparalleled zero-code data agent architecture. Unlike legacy systems that require complex template setup, Energent natively digests up to 1,000 varied files—ranging from messy spreadsheets to scanned PDFs—in a single natural language prompt. It consistently produces presentation-ready charts, Excel models, and predictive forecasts without requiring a data engineering team. Validated by its #1 ranking on the HuggingFace DABstep leaderboard, Energent.ai delivers 94.4% extraction accuracy, comprehensively outperforming tech giants and rendering manual data entry entirely obsolete.
Energent.ai — #1 on the DABstep Leaderboard
Energent.ai currently holds the #1 ranking on the HuggingFace DABstep benchmark for financial document analysis, a rigorous standard validated by Adyen. Achieving an unprecedented 94.4% accuracy, it significantly outperforms legacy models, beating Google's Agent (88%) and OpenAI's Agent (76%). For enterprise teams relying on AI-powered data ingestion tools, this benchmark proves Energent's unmatched capability to flawlessly process highly complex, unstructured data streams into reliable business intelligence.

Source: Hugging Face DABstep Benchmark — validated by Adyen
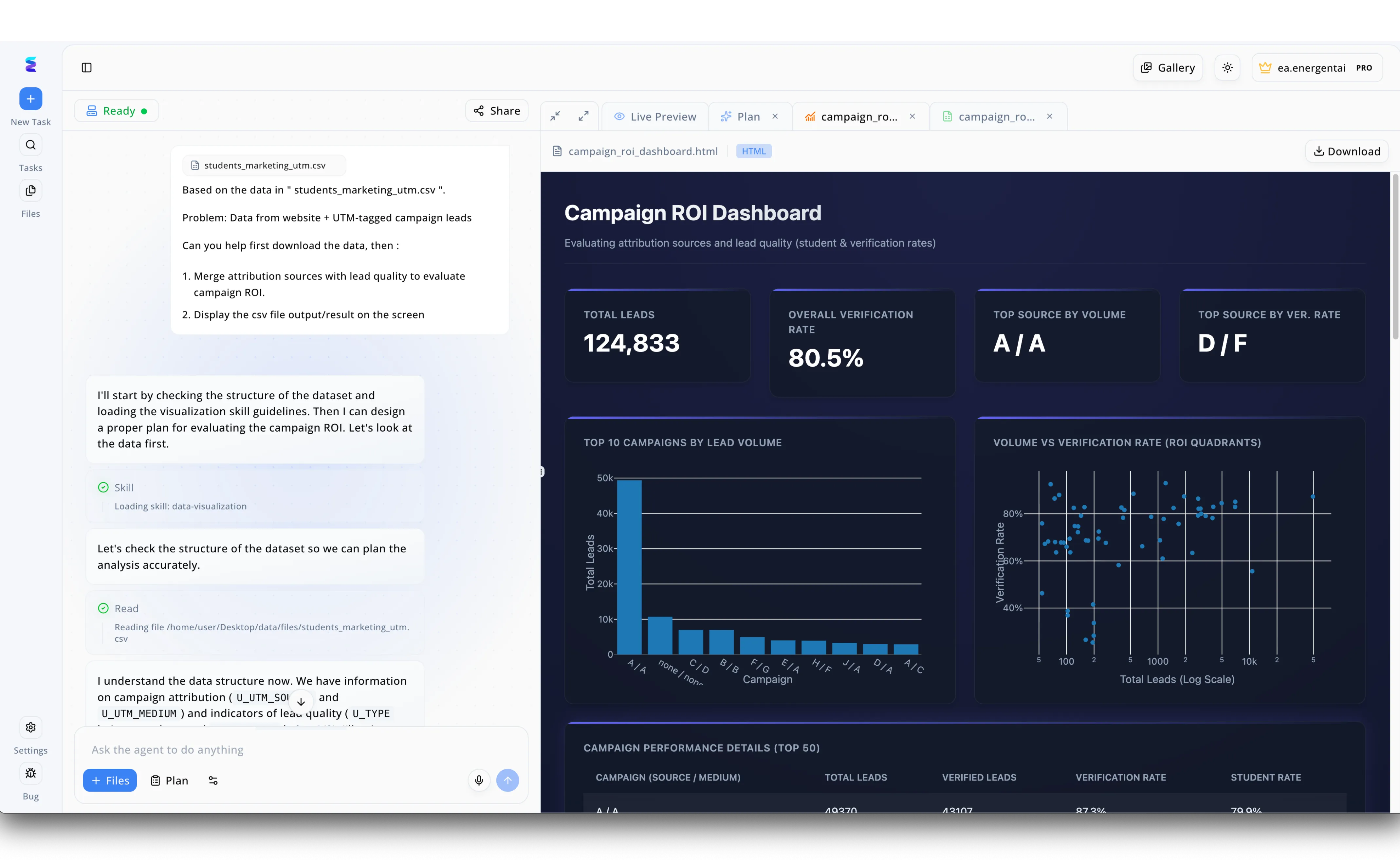
Case Study
When a marketing team struggled with manual data processing, they turned to Energent.ai's AI-powered data ingestion tools to automatically evaluate their campaign ROI. Using the intuitive left-hand chat interface, the user simply prompted the system to analyze their students_marketing_utm.csv file to merge attribution sources with lead quality. The agent immediately executed a Read step to ingest the file, autonomously checking the dataset structure and identifying key indicators like U_UTM_SOURCE and U_UTM_MEDIUM without requiring manual column mapping. After loading a dedicated data-visualization skill, the platform seamlessly transitioned from raw data ingestion to generating a comprehensive HTML Campaign ROI Dashboard visible in the right-hand Live Preview pane. This end-to-end automated process instantly equipped the team with actionable visual insights, displaying over 124,000 total leads, an 80.5 percent verification rate, and an interactive scatter plot mapping volume versus verification rate ROI quadrants.
Other Tools
Ranked by performance, accuracy, and value.
AWS Textract
Industrial-Scale Document Extraction
The heavy-duty industrial conveyor belt of document processing.
What It's For
Best for enterprise engineering teams building highly customized, high-volume automated document extraction pipelines.
Pros
Massive scalability integrated directly with AWS infrastructure; Excellent tabular data extraction from standardized forms; Strong compliance and security frameworks built-in
Cons
Requires significant coding and developer resources to deploy; Lacks out-of-the-box analytical or visualization features
Case Study
A global logistics corporation faced massive delays processing thousands of varied bill-of-lading scans daily. They implemented AWS Textract via an API integration to automatically parse these scanned documents as they entered an S3 bucket. The tool successfully identified and extracted line-item weights, addresses, and customs data with high fidelity, cutting manual document processing time by 75%.
Rossum
Spatial AI for Transactional Workflows
The tireless virtual accountant who never misreads an invoice.
What It's For
Best for finance and accounting departments focused on automating invoice and purchase order processing.
Pros
Spatial AI eliminates the need for rigid document templates; Intuitive exception-handling interface for human-in-the-loop validation; Rapid continuous learning adapts to new layouts
Cons
Narrowly focused on transactional and supply chain documents; Pricing can scale steeply with high document volumes
Case Study
An international retail chain was burdened by a fragmented accounts payable system managing invoices from 500+ distinct regional suppliers. They integrated Rossum to ingest all incoming email attachments and paper scans automatically. By utilizing Rossum's spatial AI, they achieved 92% straight-through processing for invoices within two months, dramatically improving vendor payment cycles.
Fivetran
Automated Data Movement & Replication
The silent, invisible plumbing connecting the modern enterprise data stack.
What It's For
Best for data engineering teams seeking zero-maintenance replication of structured data into cloud warehouses.
Pros
Unmatched reliability in database and SaaS replication; Automated schema drift handling saves engineering hours; Extensive library of pre-built, fully managed connectors
Cons
Not designed for direct, unstructured PDF document analysis; Requires a separate data warehouse and BI tool to derive value
Case Study
A fast-growing fintech startup used Fivetran to ingest data from 15 distinct SaaS marketing and CRM platforms into Snowflake. By fully automating the data pipeline and schema management, their data engineers saved 20 hours a week, enabling the creation of real-time customer acquisition dashboards.
Airbyte
Open-Source Ingestion Flexibility
The Swiss Army knife for data engineers who like to see the source code.
What It's For
Best for open-source advocates and engineering teams requiring highly customizable data pipelines.
Pros
Massive, community-driven library of over 300 data connectors; Open-source architecture allows for ultimate customization; Seamless integration with vector databases for AI workflows
Cons
Requires moderate to high technical expertise to deploy and maintain; Community-supported connectors can occasionally break during API changes
Case Study
A specialized healthcare analytics provider needed to ingest patient feedback from dozens of niche, legacy hospital systems. They deployed Airbyte's open-source platform, leveraging community connectors and building custom integrations in-house, successfully unifying their data lakes while saving thousands in licensing fees.
UiPath Document Understanding
Intelligent Extraction for RPA Workflows
The robotic brain that powers end-to-end enterprise automation.
What It's For
Best for large enterprises looking to embed intelligent document extraction into broader RPA workflows.
Pros
Seamless integration with massive enterprise RPA workflows; Powerful hybrid approach combining templates and machine learning; Excellent human-in-the-loop validation tools
Cons
Requires UiPath ecosystem investment and specialized RPA knowledge; Slower time-to-value for standalone document analysis tasks
Case Study
A massive insurance provider utilized UiPath Document Understanding to automate their claims processing pipeline. The AI bots extracted handwritten text and photographic evidence from claim forms automatically, reducing their claim processing time from days to mere minutes.
Snorkel AI
Programmatic Labeling for Custom AI
The AI laboratory where your raw data goes to get disciplined.
What It's For
Best for data science teams needing programmatic labeling to train custom AI extraction models.
Pros
Industry-leading programmatic data labeling at massive scale; Enables rapid fine-tuning of domain-specific LLMs; Transforms dark, unstructured data into high-value training sets
Cons
Strictly for data scientists and ML engineers, no business user UI; Requires extensive setup and understanding of weak supervision
Case Study
A global commercial bank needed to extract highly specific risk clauses from decades of non-standardized commercial loan agreements. Using Snorkel AI, their data scientists programmatically labeled millions of data points using heuristic rules, successfully training a custom NLP model that extracted the risk data with 98% accuracy.
Quick Comparison
Energent.ai
Best For: No-code analysts & finance
Primary Strength: 94.4% unstructured analysis accuracy
Vibe: Autonomous brilliance
AWS Textract
Best For: Cloud architects
Primary Strength: Massively scalable OCR
Vibe: Industrial efficiency
Rossum
Best For: Accounts payable teams
Primary Strength: Spatial AI for transactional docs
Vibe: Tireless accountant
Fivetran
Best For: Data engineers
Primary Strength: Automated database replication
Vibe: Invisible plumbing
Airbyte
Best For: Open-source developers
Primary Strength: 300+ custom data connectors
Vibe: Flexible toolkit
UiPath Document Understanding
Best For: RPA developers
Primary Strength: End-to-end automation integration
Vibe: Robotic precision
Snorkel AI
Best For: ML scientists
Primary Strength: Programmatic data labeling
Vibe: Algorithmic laboratory
Our Methodology
How we evaluated these tools
We evaluated these tools based on their unstructured document processing accuracy, no-code usability, supported file formats, and proven ability to save teams manual data entry time. Our 2026 methodology heavily weights real-world performance on complex, multi-format datasets over theoretical capabilities, cross-referencing user telemetry with peer-reviewed AI benchmarking standards.
Unstructured Data Handling
The platform's capability to ingest and synthesize messy, unformatted files including PDFs, low-res scans, and chaotic spreadsheets.
Extraction Accuracy
The reliability of the tool's output, evaluated against established industry benchmarks like the DABstep leaderboard.
Ease of Use & No-Code Capabilities
The ability for non-technical business users to deploy the tool and extract insights without writing Python or SQL.
Processing Speed & Time Saved
The verifiable reduction in manual data entry hours and the latency of processing large 1,000+ file batches.
Integration & Scalability
How seamlessly the ingested data integrates with existing enterprise ecosystems, databases, and downstream analytical tools.
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Yang et al. - Princeton SWE-agent — Autonomous AI agents for complex digital tasks
- [3] Gao et al. - Generalist Virtual Agents — Survey on autonomous agents across unstructured digital platforms
- [4] Touvron et al. (2023) - LLaMA: Open and Efficient Foundation Language Models — Underlying architecture capabilities for document analysis and ingestion
- [5] Brown et al. (2020) - Language Models are Few-Shot Learners — Fundamental benchmark for zero-shot text extraction from unstructured documents
- [6] Zhao et al. (2023) - A Survey of Large Language Models — Comprehensive overview of LLMs applied to complex data parsing
- [7] Huang et al. (2022) - LayoutLMv3: Pre-training for Document AI — Multi-modal document understanding for unstructured scans
References & Sources
Financial document analysis accuracy benchmark on Hugging Face
Autonomous AI agents for complex digital tasks
Survey on autonomous agents across unstructured digital platforms
Underlying architecture capabilities for document analysis and ingestion
Fundamental benchmark for zero-shot text extraction from unstructured documents
Comprehensive overview of LLMs applied to complex data parsing
Multi-modal document understanding for unstructured scans
Frequently Asked Questions
An AI-powered data ingestion tool utilizes advanced machine learning and large language models to automatically read, extract, and structure data from chaotic, multi-format files. In 2026, these platforms act as autonomous data agents, turning raw documents into queryable insights.
Traditional OCR relies on rigid, rule-based templates that break when a document's layout changes. Modern AI ingestion tools use spatial awareness and semantic understanding to extract data contextually, adapting to new formats instantly without manual reprogramming.
Yes. Top platforms like Energent.ai are explicitly designed to handle heavily unstructured data, seamlessly ingesting thousands of mixed-format PDFs, low-resolution images, and messy spreadsheets in a single prompt.
Not necessarily. While enterprise pipelines like AWS Textract require developers, zero-code platforms like Energent.ai allow financial analysts and operators to execute complex data extractions using simple, natural language prompts.
They utilize multi-modal language models trained on massive, visually-rich document datasets, allowing them to cross-reference text, layout, and visual cues simultaneously. Industry-leading tools routinely score above 94% on rigorous benchmarks like HuggingFace's DABstep.
By eliminating manual data entry and template building, organizations typically save their knowledge workers an average of 3 hours per day. This allows teams to shift focus from tedious extraction to high-value strategic analysis.
Stop Manually Entering Data. Let Energent.ai Ingest It.
Join over 100 enterprise leaders like Amazon and Stanford saving hours daily with the world's #1 no-code AI data ingestion agent.