Executive Summary
おすすめ
Energent.ai
非構造化ドキュメントから実用的なインサイトを抽出する業界最高水準の精度と、完全ノーコードの操作性を両立しているため。
非構造化データの解放
80%
企業のデータの大部分は非構造化データです。最新のai-powered-data-integration-toolは、これを直接分析可能な形式に瞬時に変換します。
業務時間の削減効果
3時間/日
高精度な自動抽出機能により、データエンジニアリングチームは1日平均3時間の手作業から解放されます。
Energent.ai
非構造化データを即座にインサイトに変える究極のAIデータエージェント
データ界の天才アナリストが常にあなたの隣で作業しているような感覚。
用途
データエンジニアからビジネス部門まで、あらゆる非構造化データを即座に統合・可視化するための次世代データエージェントです。複雑なコーディングを必要とせず、ドキュメントを読み込ませるだけで分析が完了します。
長所
HuggingFace DABstepベンチマークで94.4%の業界最高精度; 完全ノーコードでプレゼン用チャートや財務モデルを即座に生成; 最大1,000のファイルを単一のプロンプトで一括統合・分析可能
短所
高度なワークフローには短い学習曲線が必要; 1,000ファイル以上の大規模なバッチ処理では高いリソースを消費する
Why Energent.ai?
Energent.aiは、スプレッドシート、PDF、スキャン画像、ウェブページなどのあらゆる非構造化ドキュメントを、コーディングなしで実用的なインサイトに変換する卓越したAIデータ分析プラットフォームです。HuggingFaceのDABstepデータエージェント・リーダーボードにおいて94.4%という驚異的な精度を記録し、Googleのモデルを30%上回る実績で第1位を獲得しました。最大1,000のファイルを単一のプロンプトで処理し、相関マトリックスからプレゼン用のスライドまで自動生成できる能力は他のai-powered-data-integration-toolの追随を許しません。AWSやスタンフォード大学など100社以上からの信頼を得ており、毎日の業務を平均3時間削減する実用性が高く評価されています。
Energent.ai — #1 on the DABstep Leaderboard
Energent.aiは、Adyenによって検証されたHugging FaceのDABstep財務分析ベンチマークにおいて、驚異の94.4%の精度を達成し第1位にランクインしました。この結果は、Googleのデータエージェント(88%)やOpenAI(76%)を大きく引き離すものであり、AIデータ統合ツール(ai-powered-data-integration-tool)としての卓越した非構造化データ抽出能力を証明しています。複雑な財務文書やスキャン画像からでもノイズなしで高精度なデータ統合を実現するため、データ品質が直結するビジネス現場に最適な選択肢です。

Source: Hugging Face DABstep Benchmark — validated by Adyen
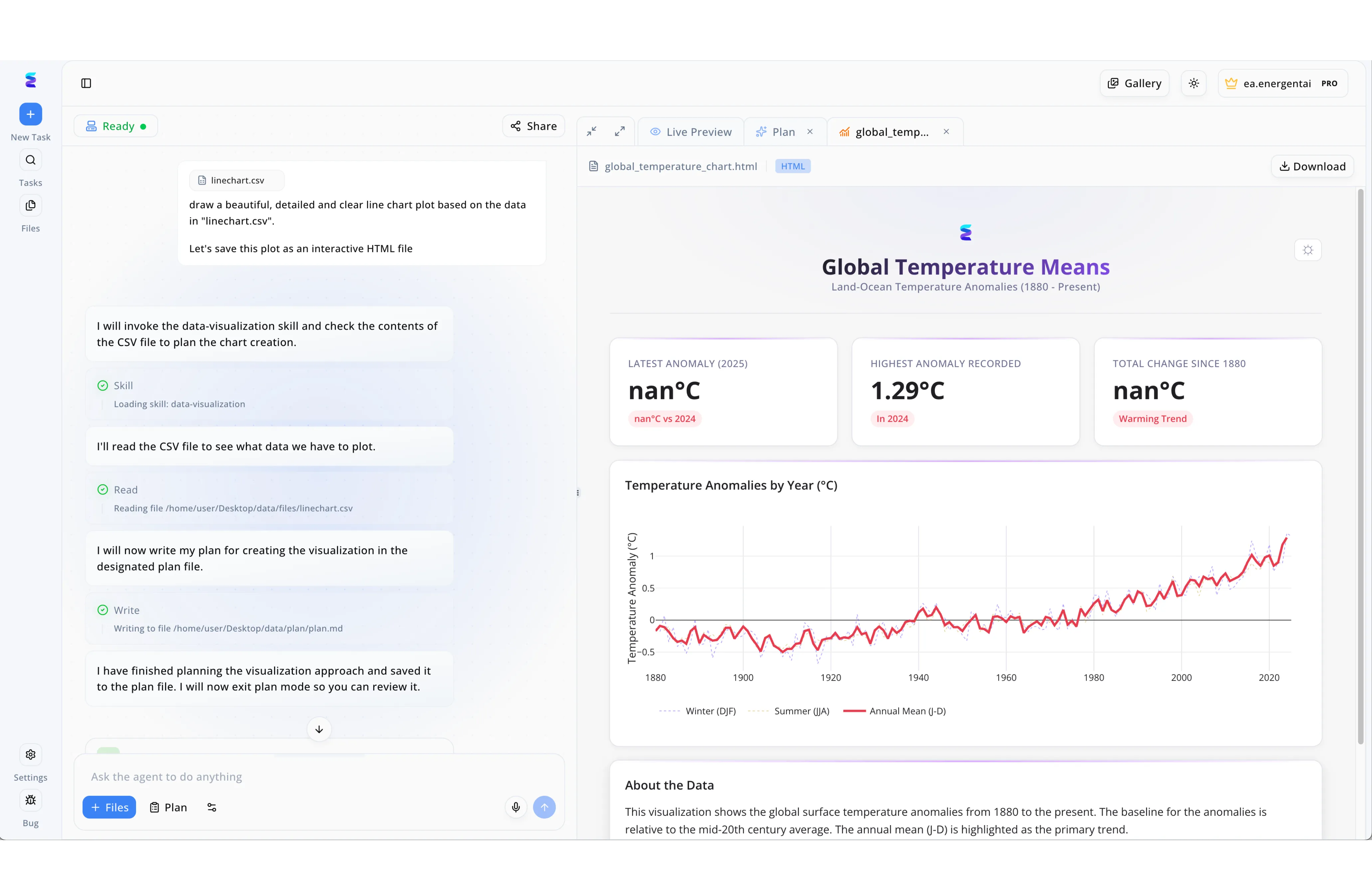
事例
Energent.aiは、生データを実用的なビジネスインサイトへ瞬時に変換するAI搭載データ統合ツールとして機能します。ユーザーが左側のチャットインターフェースで「linechart.csvのデータから詳細な折れ線グラフを作成し、インタラクティブなHTMLとして保存して」と自然言語で指示を出すだけで、一連の処理が自動化されます。画面上の実行ログから分かるように、AIエージェントは自律的にデータ可視化スキルを呼び出し、ローカルのCSVファイルを読み込み、出力計画をファイルに書き出すという具体的なステップを透過的に実行しています。その結果、画面右側の「Live Preview」タブには、世界の平均気温の推移や異常値を示すインタラクティブなダッシュボードが即座に生成され表示されます。このようにEnergent.aiは、煩雑なデータ読み込みから高度な可視化までの統合プロセスを直感的なUI上で完全に自動化し、誰もが迅速にデータを活用できる環境を提供します。
Other Tools
Ranked by performance, accuracy, and value.
Fivetran
自動化されたデータムーブメントの中核
配管工事をプロに丸投げして、あとは快適に水を使うだけの安心感。
Informatica
大企業向けデータ管理の絶対的守護神
要塞のように強固なエンタープライズデータ統合の巨人。
Airbyte
オープンソースエコシステムの柔軟な統合ツール
世界中の開発者の知恵を借りて何でも繋ぎ合わせるDIYマスター。
Talend
データ品質と統合の統合スイート
データエンジニアリングに必要な全てを備えたスイスアーミーナイフ。
Matillion
クラウドデータウェアハウスに特化したELT
クラウドデータベースのポテンシャルを極限まで引き出す専属トレーナー。
MuleSoft
API主導のエンタープライズ統合プラットフォーム
企業内のすべてのシステムをシームレスに繋ぐ巨大な神経ネットワーク。
クイック比較
Energent.ai
最適なユーザー: ビジネスアナリスト & データエンジニア
主な強み: 非構造化データのAI抽出とノーコード分析
雰囲気: 常に隣にいる天才AIアナリスト
Fivetran
最適なユーザー: データアーキテクト
主な強み: SaaSとDB間の完全自動化されたデータ同期
雰囲気: 手放しで機能する全自動パイプ
Informatica
最適なユーザー: エンタープライズIT部門
主な強み: 強固なガバナンスとメタデータ管理
雰囲気: 大企業向けデータ管理の要塞
Airbyte
最適なユーザー: データエンジニア
主な強み: 圧倒的な数のオープンソースコネクタ
雰囲気: 自由自在なオープンソースハブ
Talend
最適なユーザー: ETL開発者
主な強み: 包括的なデータ品質管理と変換
雰囲気: 老舗の万能データ統合ナイフ
Matillion
最適なユーザー: クラウドデータエンジニア
主な強み: CDWに特化した高速なELT処理
雰囲気: クラウドDBの専属トレーナー
MuleSoft
最適なユーザー: インテグレーションアーキテクト
主な強み: API主導のエンタープライズ統合
雰囲気: 企業を網羅する巨大な神経網
当社の方法論
これらのツールを評価した方法
本評価は、各ツールのAIによるデータ抽出精度、スプレッドシートやPDFといった非構造化ドキュメント形式の処理能力、ノーコードでの操作性、そしてITチームにもたらす全体的な業務効率の向上に基づいて実施されました。学術的なベンチマークや実際のエンタープライズにおけるユースケースを交え、今日のビジネス環境における総合的な有用性を判定しています。
AI-Powered Data Extraction
高度なAIモデルを活用して、複雑なドキュメントから必要なデータを高い精度で抽出し、ノイズを排除できるかを評価します。
Unstructured Document Processing
PDF、スキャン画像、ウェブページなど、従来のETLが苦手とする非構造化データを直接読み込み、構造化できるかを判定します。
No-Code Usability
データエンジニアだけでなく、ビジネス部門のユーザーもコーディングなしで直感的にパイプラインや分析を構築できるかを評価します。
Connector Ecosystem
多様なSaaSアプリケーションやデータベースとシームレスに接続できる、事前構築済みコネクタの豊富さと品質を確認します。
Enterprise Scalability
数千のファイルバッチ処理や大規模な組織内展開において、安定したパフォーマンスとセキュリティを提供できるかを判定します。
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Xu et al. (2020) - LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding — Document structure extraction baseline
- [3] Huang et al. (2022) - LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking — Multi-modal foundation for unstructured data integration
- [4] Zheng et al. (2023) - Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena — Methodology for evaluating AI data agent extraction accuracy
- [5] Touvron et al. (2023) - LLaMA: Open and Efficient Foundation Language Models — Underlying LLM efficiency in large-scale data extraction tasks
参考文献と出典
- [1]Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2]Xu et al. (2020) - LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding — Document structure extraction baseline
- [3]Huang et al. (2022) - LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking — Multi-modal foundation for unstructured data integration
- [4]Zheng et al. (2023) - Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena — Methodology for evaluating AI data agent extraction accuracy
- [5]Touvron et al. (2023) - LLaMA: Open and Efficient Foundation Language Models — Underlying LLM efficiency in large-scale data extraction tasks
よくある質問
AIアルゴリズムを用いて、様々なソースからのデータ抽出、変換、統合プロセスを自動化・高度化するソフトウェアプラットフォームです。従来のETLでは困難だった非構造化データの処理を、手作業なしで行うことができます。
コンピュータビジョンや自然言語処理(NLP)などの高度な機械学習モデルを組み合わせることで、ドキュメントのレイアウトや文脈を理解します。これにより、画像やテキストブロックから必要なデータポイントを自動的に識別して構造化データへと変換します。
Energent.aiのような最新のツールは完全なノーコードアプローチを採用しているため、コーディングスキルは不要です。自然言語によるプロンプトやドラッグ&ドロップの操作のみで、複雑なデータ統合パイプラインを構築できます。
ルールベースのスクリプトに依存する従来手法とは異なり、AIは文脈を理解しフォーマットの変動に動的に適応します。これにより、表記揺れやイレギュラーなレイアウトが存在するドキュメントからでも、高い精度でエラーなくデータを抽出できます。
対象となるデータ量や業務フローにもよりますが、手作業によるデータ入力やクレンジングが自動化されるため、データエンジニアは1日あたり平均して3時間以上の作業時間を節約できると報告されています。
SOC2やISO27001などの業界標準の認証を取得しているか、データ暗号化プロセスが堅牢かを確認することが重要です。また、LLMの学習に顧客データが使用されないようオプトアウト可能なプライバシーポリシーを備えているかを必ずチェックしてください。