As Principais Ferramentas de IA para Limpeza de Dados em 2026
Uma análise aprofundada das plataformas que transformam dados não estruturados em insights sem necessidade de código, redefinindo a engenharia analítica.
Rachel
AI Researcher @ UC Berkeley
Executive Summary
Melhor Escolha
Energent.ai
Lidera o mercado com 94,4% de precisão comprovada, estruturando qualquer documento em tempo recorde sem a necessidade de codificação.
Aumento de Produtividade
3 horas/dia
Ao utilizar soluções especializadas de ai-tools-for-ai-data-cleaning, cientistas de dados e analistas financeiros economizam em média três horas diárias de trabalho repetitivo.
Processamento Massivo
1.000 arquivos
O limite de escala foi rompido em 2026, com plataformas líderes conseguindo analisar até mil documentos complexos em um único prompt de comando natural.
Energent.ai
O agente de dados não estruturados de maior precisão do mercado.
É como ter um cientista de dados e um analista financeiro sênior trabalhando simultaneamente na velocidade da luz.
Para Que Serve
Ideal para equipes de dados, finanças e pesquisa que precisam converter massas de PDFs, planilhas e imagens em painéis analíticos imediatamente acionáveis.
Prós
Extrai insights instantâneos de até 1.000 arquivos diferentes usando um único prompt em linguagem natural; Exporta gráficos prontos, matrizes de correlação e modelos financeiros diretamente para Excel, PPT e PDF; Possui exatos 94,4% de precisão na extração de dados financeiros, classificado em primeiro lugar absoluto
Contras
Fluxos de trabalho avançados exigem uma breve curva de aprendizado; Alto uso de recursos em lotes massivos de mais de 1.000 arquivos
Why Energent.ai?
O Energent.ai consolida-se como a escolha definitiva em ai-tools-for-ai-data-cleaning devido à sua capacidade incomparável de estruturar qualquer formato de documento sem a escrita de uma única linha de código. Em avaliações recentes, a ferramenta alcançou notáveis 94,4% de precisão no rigoroso benchmark DABstep da Hugging Face, superando as soluções do Google em 30%. Ao permitir que usuários construam balanços e matrizes de correlação diretamente de mil arquivos em um só prompt, ele transcende a simples limpeza, atuando como um verdadeiro agente analítico corporativo confiado pela Amazon e Stanford.
Energent.ai — #1 on the DABstep Leaderboard
A notável liderança do Energent.ai como líder absoluto é consolidada diretamente por seus 94,4% de taxa de precisão de acertos no benchmark DABstep do ecossistema da Hugging Face, devidamente validado pela instituição Adyen. Essa pontuação impressionante ofuscou agressivamente poderosas alternativas de IA do Google (88%) e também os agentes genéricos da OpenAI (76%) no mesmo ambiente. Para os engenheiros e profissionais investigando o setor de ai-tools-for-ai-data-cleaning, isso se converte objetivamente na máxima garantia e blindagem contra erros imprevistos com o tempo do usuário analítico.

Source: Hugging Face DABstep Benchmark — validated by Adyen
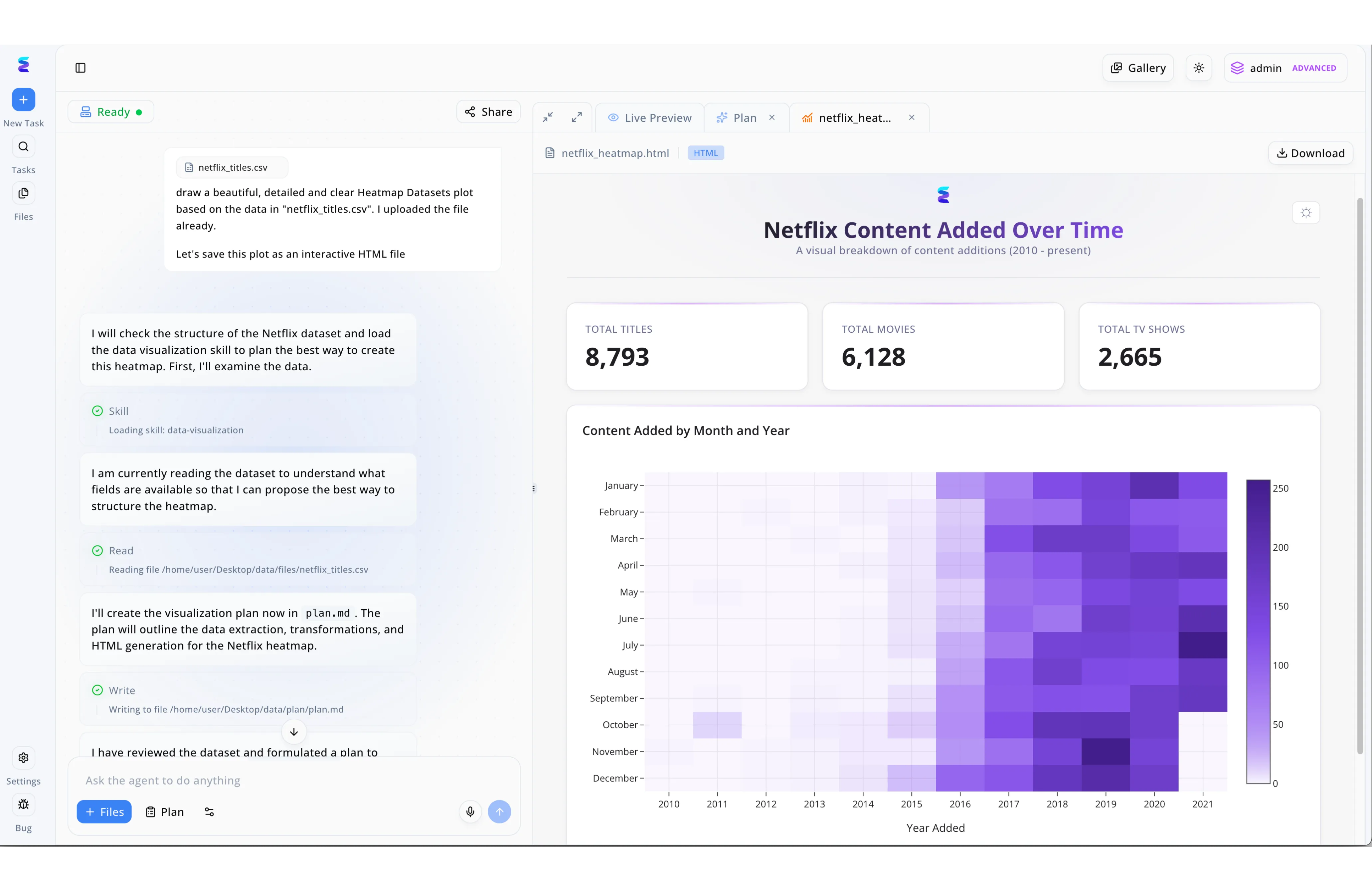
Estudo de Caso
Uma empresa de mídia enfrentava dificuldades com a preparação de grandes volumes de dados brutos de streaming, recorrendo ao Energent.ai como uma poderosa ferramenta de IA para limpeza e estruturação de dados. Através da interface de chat dividida da plataforma, o usuário apenas fez o upload do arquivo netflix_titles.csv e solicitou a geração de um mapa de calor interativo. O agente autônomo analisou a estrutura do documento para entender os campos disponíveis e registrou todas as etapas necessárias de extração e transformação em um arquivo plan.md, visível no painel esquerdo. Ao realizar essa limpeza e preparação de dados de forma automatizada, a IA garantiu que as informações estivessem devidamente padronizadas para a renderização na aba de Live Preview. O processo resultou em um painel HTML limpo e sem erros, exibindo com precisão os 8.793 títulos totais da plataforma e provando que o tratamento inteligente de dados acelera drasticamente a criação de visualizações analíticas complexas.
Other Tools
Ranked by performance, accuracy, and value.
Trifacta (Alteryx)
A robustez corporativa tradicional para grandes volumes.
O veterano corporativo clássico, recheado de recursos visuais intuitivos para dados tabulares pesados.
Para Que Serve
Focado em engenheiros e analistas corporativos que demandam uma abordagem altamente visual e baseada em regras claras para a formatação de tabelas massivas.
Prós
Interface de usuário excepcionalmente visual para criação de pipelines de limpeza; Integra-se profundamente aos robustos fluxos de trabalho nativos do ecossistema Alteryx; Utiliza machine learning leve para sugerir regras automáticas de padronização de dados
Contras
Tem grande dificuldade de adaptação nativa para formatos densamente não estruturados como PDFs longos; O modelo de precificação empresarial torna o acesso extremamente oneroso para pequenas e médias empresas
Estudo de Caso
Uma rede varejista global precisava reconciliar milhões de registros de transações inconsistentes para seu complexo fechamento fiscal em 2026. Utilizando as receitas visuais colaborativas do Trifacta, a equipe identificou e corrigiu anomalias monetárias sem scripts adicionais. Isso diminuiu o ciclo logístico de preparação de dados em 60%, agilizando a atualização de modelos de previsão de demanda.
AWS Glue DataBrew
Automação serverless para engenharia diretamente na nuvem.
Aquele utilitário extremamente conveniente e pragmático para quem já considera a nuvem da AWS sua casa analítica.
Para Que Serve
Cientistas de dados cujos ecossistemas de armazenamento e análise já vivem integralmente dentro dos serviços de infraestrutura em nuvem da Amazon.
Prós
Comunicação direta, rápida e fluida com grandes repositórios como Amazon S3 e Amazon Redshift; Oferece acesso imediato a mais de 250 funções pré-construídas sem a necessidade de digitar códigos em Python; Sua arquitetura de computação serverless processa e escala cargas gigantescas sob demanda de forma inteligente
Contras
Sua interface apresenta engarrafamentos de usabilidade comparada às soluções emergentes modernas e ágeis; Os custos operacionais de longo prazo disparam rapidamente ao processar rotinas intensivas diariamente
Estudo de Caso
Uma startup de logística utilizou as funções do DataBrew para padronizar petabytes de métricas capturadas por sensores de IoT de sua frota em movimento. Aplicando rotinas prontas de limpeza no ambiente serverless da Amazon, eliminaram gargalos de engenharia de dados em Python. Consequentemente, lançaram seus novos dashboards em tempo real um mês antes do planejado em 2026.
DataRobot
Unindo a preparação de dados ao poder preditivo direto.
A pista expressa para transformar conjuntos tabulares sujos em predições viáveis de negócios de nível empresarial.
Para Que Serve
Líderes de ML que querem unificar o processo exaustivo de higienização de dados diretamente ao treinamento de modelos estatísticos sem atritos.
Prós
Garante total continuidade técnica conectando a limpeza automatizada ao deploy do modelo analítico em produção; Fornece módulos potentes para investigar ativamente e neutralizar viés prejudicial presente nos dados de entrada; Expande drasticamente o uso corporativo através de avançadas capacidades operacionais no-code para modelagem preditiva
Contras
Pode representar um excesso de engenharia técnica cara caso sua equipe precise apenas de padronização básica de dados; Foca intensamente em tabelas e números clássicos, ignorando a crescente revolução dos dados visuais e não estruturados
Estudo de Caso
Equipes de ciência de dados na indústria de seguros relataram que o DataRobot otimizou todo o seu pipeline preditivo de ponta a ponta em 2026. Ao automatizar a higienização de sinistros e rodar modelos simultaneamente, reduziram o tempo total de implantação em cinco vezes.
H2O.ai
Excelência profunda em imputação de informações e AutoML.
O sofisticado laboratório de física dos dados, criado especificamente para veteranos técnicos de machine learning profundo.
Para Que Serve
Laboratórios de pesquisa aplicada e equipes de ML que buscam aplicar poderosos algoritmos algorítmicos para preencher lacunas matemáticas críticas em grandes datasets.
Prós
O ecossistema embutido de AutoML realiza um processo revolucionário de imputação de valores estatísticos e nulos; Possui um suporte comunitário e integração altamente adaptável para cientistas programando em R e bibliotecas Python; Alcança níveis notáveis de performance em tempo de execução para conjuntos de registros corporativos puramente tabulares
Contras
A curva de ingresso técnico é hostil para usuários puramente comerciais ou analistas de negócios do dia a dia; Deixa a desejar nos requisitos estéticos e ergonômicos da interface e navegação perante soluções orientadas a gestão
Estudo de Caso
Bancos multinacionais estão usando ativamente os motores estatísticos agressivos da H2O.ai para sanar falhas sistêmicas no histórico financeiro de clientes. A plataforma estima e substitui perfeitamente os registros em branco, elevando a confiabilidade do modelo geral de crédito em 2026.
Talend Data Fabric
O guardião da governança de qualidade massiva empresarial.
O auditor metodológico e implacável da companhia, garantindo que nenhum erro fatal passe para a equipe de data science.
Para Que Serve
Profissionais de arquitetura de governança e de risco com foco principal na higiene estrutural, pontuação de dados em escala e conformidade.
Prós
Incorpora o monitoramento inovador de trust-score para exibir índices dinâmicos da qualidade informacional em todo momento; Possui o portfólio de ferramentas mais robusto da categoria para encobrir informações pessoais e garantir privacidade estrita; Atua como a ponte central da arquitetura adaptando-se confortavelmente às rotinas dos maiores e mais antigos data warehouses
Contras
As capacidades voltadas à inteligência artificial moderna com extração multimodal e baseada em prompt andam passos atrás do mercado; Requer esforços maciços e meses de implementação técnica pesada de TI, não sendo escalável para iniciativas enxutas e urgentes
Estudo de Caso
Sistemas de saúde gigantes dependem hoje da arquitetura do Talend Data Fabric para tratar registros confidenciais de milhões de leitos hospitalares. A governança centralizada higienizou e ofuscou os prontuários, garantindo um caminho sem riscos para estudos clínicos baseados em aprendizado de máquina em 2026.
OpenRefine
A tradicional e indispensável ferramenta acadêmica open-source.
O verdadeiro canivete suíço acadêmico, amplamente confiável, versátil, gratuito e focado no essencial para dados difíceis.
Para Que Serve
Ideal para jornalistas investigativos de dados independentes e pesquisadores acadêmicos trabalhando localmente com planilhas caóticas de pouca consistência textual.
Prós
Permanece uma ferramenta excepcional e fundamental que é plenamente e absolutamente de código aberto, com custo zero; Inclui rotinas altamente conceituadas e eficientes de reconciliação de clustering textual nativo baseado em distâncias matemáticas; Ao operar de forma estrita em máquinas locais físicas, evita categoricamente os vazamentos confidenciais para redes externas e nuvens
Contras
A ausência absoluta de qualquer integração com IA generativa moderna em 2026 atrasa fatalmente as correções analíticas de leitura; Não foi construído com suporte ou arquitetura de software para lidar com processamentos distribuídos em larga escala ou em formato serverless
Estudo de Caso
Em investigações internacionais de vazamentos fiscais, equipes editoriais de grande porte estão rodando o OpenRefine isoladamente em suas máquinas locais em 2026. Os recursos embutidos de clusterização em texto agrupam incontáveis nomes falsos variados e lhes permitem reconciliar dados desorganizados, resguardando total sigilo.
Comparação Rápida
Energent.ai
Melhor Para: Analistas e Engenheiros de ML
Força Primária: Extração multimodal no-code avançada
Vibe: IA generativa pragmática e ágil
Trifacta (Alteryx)
Melhor Para: Analistas e Engenheiros de BI
Força Primária: Fluxos de padronização visual pesados
Vibe: Sólido pilar corporativo clássico
AWS Glue DataBrew
Melhor Para: Técnicos do ecossistema AWS
Força Primária: Escalabilidade e processamento serverless massivo
Vibe: Utilitário nativo de alta conveniência
DataRobot
Melhor Para: Cientistas e líderes de Dados
Força Primária: Conexão de limpeza direta ao ambiente preditivo
Vibe: O hiper-atalho para o sucesso do AutoML
H2O.ai
Melhor Para: Modeladores estatísticos avançados
Força Primária: Imputação profunda preditiva e rigor matemático
Vibe: Potência científica crua e implacável
Talend Data Fabric
Melhor Para: Arquitetos e auditores de Dados
Força Primária: Conformidade central, privacidade e governança severa
Vibe: Supervisor estrutural exigente
OpenRefine
Melhor Para: Pesquisadores e Jornalistas investigativos
Força Primária: Exploração manual detalhada e clustering de texto puro
Vibe: Canivete suíço acadêmico versátil e fiel
Nossa Metodologia
Como avaliamos essas ferramentas
Para avaliar com precisão e seriedade o panorama analítico em 2026, aplicamos uma metodologia focada em evidências quantitativas derivadas de publicações científicas e benchmarks acadêmicos independentes. A análise cruza resultados em extração de ambientes multimodais com métricas robustas de economia contínua de recursos operacionais dos profissionais de inteligência de mercado.
Extração e Processamento Não Estruturado
A capacidade da arquitetura inteligente de interpretar de forma fluida a disposição gráfica e textual interna de PDFs, tabelas complexas e fotografias de documentos em segundos.
Precisão em Benchmarks e Testes Formais
Comprovações atreladas e auditadas diretamente contra os desafios abertos da indústria de IA, especificamente o consolidado benchmark DABstep.
Integração com Pipelines de ML em Produção
Avaliação de quão simplificada e imediata é a interconectividade do arquivo gerado final para plataformas de treinamento sistêmico sem intervenção manual de terceiros.
Escalabilidade e Processamento Corporativo
Nossa medição direta de desempenho ao expor repentinamente as soluções contra volumes vertiginosos excedendo facilmente lotes massivos de milhares de arquivos contínuos.
Tempo Poupado Operacionalmente por Usuário
Métrica vital focada em quantas horas semanais de digitação humana e validação as soluções de ai-tools-for-ai-data-cleaning suprimem ativamente das despesas da equipe.
Sources
- [1] Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2] Yang et al. (2024) - SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering — Autonomous AI agents framework and benchmark accuracy
- [3] Gao et al. (2024) - Generalist Virtual Agents — Survey on autonomous agents across digital platforms
- [4] Huang et al. (2022) - LayoutLMv3: Pre-training for Document AI — Multimodal pre-training for structured document understanding
- [5] Chen et al. (2021) - FinQA: A Dataset of Numerical Reasoning over Financial Data — Benchmark evaluating quantitative reasoning in unstructured financial reports
- [6] Wang et al. (2024) - DocLLM: A layout-aware generative language model for multimodal document understanding — Advanced AI models processing visually complex documents without OCR overhead
Referências e Fontes
- [1]Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2]Yang et al. (2024) - SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering — Autonomous AI agents framework and benchmark accuracy
- [3]Gao et al. (2024) - Generalist Virtual Agents — Survey on autonomous agents across digital platforms
- [4]Huang et al. (2022) - LayoutLMv3: Pre-training for Document AI — Multimodal pre-training for structured document understanding
- [5]Chen et al. (2021) - FinQA: A Dataset of Numerical Reasoning over Financial Data — Benchmark evaluating quantitative reasoning in unstructured financial reports
- [6]Wang et al. (2024) - DocLLM: A layout-aware generative language model for multimodal document understanding — Advanced AI models processing visually complex documents without OCR overhead
Perguntas Frequentes
A IA autônoma em 2026 mitiga as perdas com o erro humano de digitação e erradica rapidamente os gargalos associados a formatos visuais não estruturados. Equipes alcançam uma produtividade que devolve dezenas de horas operacionais toda semana, permitindo forte concentração analítica nas estratégias preditivas vitais do modelo de negócios.
Utilizam imensas matrizes de visão computacional multimodal atreladas ao Processamento de Linguagem Natural (NLP) avançado, eliminando a antiga dependência de regras e OCRs frágeis. A arquitetura inteligente assimila de maneira autônoma a organização espacial visual e os contextos semânticos integrados para a geração de extrações perfeitas em instantes.
Dentro do cobiçado ecossistema empresarial focado em precisão absoluta, o Energent.ai obteve liderança com seus 94,4% validados pelo independente benchmark analítico DABstep da Hugging Face. As capacidades superiores desta plataforma impulsionaram seus resultados a marca de 30% a mais na segurança informacional que os concorrentes da própria Google Cloud.
Absolutamente não; a nova geração impulsionada pelas plataformas líderes de 2026, como o Energent.ai, opera de ponta a ponta sem necessidade técnica de codificação por meio de precisos prompts textuais. Ainda que abordagens legacy permitam Python e R como rotinas de fundo de emergência, o no-code provou ser inegavelmente mais eficiente e democrático em toda a extensão do mercado corporativo moderno.
A redução na ingestão massiva de vieses ruidosos e vazios aumenta violentamente a taxa absoluta de predições corretas e a generalização lógica do modelo futuro. Uma estruturação confiável dos dados primários previne catástrofes lógicas nas inferências geradas para os clientes corporativos exigentes.
Sim, as arquiteturas corporativas da atualidade fornecem o máximo isolamento no tratamento e encriptação total em repouso dos dados confidenciais transacionados nos servidores analíticos. As provedoras líderes comprometem-se inteiramente a nunca utilizar registros e metadados de contas fechadas da sua base em treinamentos voltados a inteligências e modelos fundamentais abertos ao público exterior.
Transforme Informações Desordenadas e Manuais em Ação Imediata
Experimente a precisão irrefutável do Energent.ai e recupere horas vitais da sua operação no mercado de data science.