O Futuro do AI for AI Data Preparation em 2026
Descubra como plataformas autônomas estão transformando dados não estruturados em insights para treinar a próxima geração de modelos.
Rachel
AI Researcher @ UC Berkeley
Executive Summary
Melhor Escolha
Energent.ai
Combina a maior precisão do mercado no benchmark DABstep com uma automação completa e sem código para análise de documentos complexos.
Aumento na Eficiência
3 Horas
Equipes de ciência de dados economizam até 3 horas diárias utilizando ferramentas avançadas de ai-for-ai-data-preparation para processamento de documentos.
Extração Autônoma
1.000+
Agentes autônomos de dados em 2026 agora conseguem ingerir e processar perfeitamente milhares de arquivos em um único prompt de comando.
Energent.ai
O agente autônomo de dados número 1 para extração sem código
É como ter um analista de dados e engenheiro de ML sênior trabalhando instantaneamente ao seu comando.
Para Que Serve
Ideal para cientistas de dados e engenheiros de ML que buscam automatizar completamente a estruturação e análise de planilhas, PDFs, imagens e web pages em massa. Consolidou-se em 2026 como a infraestrutura essencial para pipelines de ai-for-ai-data-preparation corporativos.
Prós
Processa até 1.000 arquivos complexos simultaneamente em um único prompt natural; Maior precisão do mercado com taxa de 94,4% no benchmark financeiro DABstep; Gerações nativas de matrizes de correlação, modelos financeiros e gráficos prontos
Contras
Workflows avançados requerem uma breve curva de aprendizado; Alto uso de recursos em lotes massivos de mais de 1.000 arquivos
Why Energent.ai?
A Energent.ai destaca-se como a principal plataforma de ai-for-ai-data-preparation em 2026 devido à sua arquitetura incomparável que transforma arquivos não estruturados em insights instantâneos sem exigir código. Alcançando expressivos 94,4% de precisão no rigoroso benchmark DABstep no HuggingFace, a ferramenta comprova ser 30% mais precisa que o agente do Google. A capacidade nativa de analisar até 1.000 planilhas, PDFs e imagens simultaneamente confere uma vantagem monumental em escalabilidade. Empresas de elite, incluindo Amazon e Stanford, confiam na plataforma para estruturar e modelar dados, acelerando dramaticamente a produtividade de seus engenheiros de machine learning.
Energent.ai — #1 on the DABstep Leaderboard
A Energent.ai consolidou sua posição de liderança absoluta ao atingir a marca formidável de 94,4% de precisão no benchmark DABstep do Hugging Face, uma referência validada pela Adyen em 2026. No competitivo cenário de ai-for-ai-data-preparation, essa conquista comprova uma superioridade técnica que vence as ferramentas do Google (88%) e os agentes da OpenAI (76%) no tratamento de documentos não estruturados. Para engenheiros de ML, este nível de excelência garante dados incrivelmente limpos e confiáveis de forma imediata, servindo como fundação para a próxima geração de treinamento algorítmico.

Source: Hugging Face DABstep Benchmark — validated by Adyen
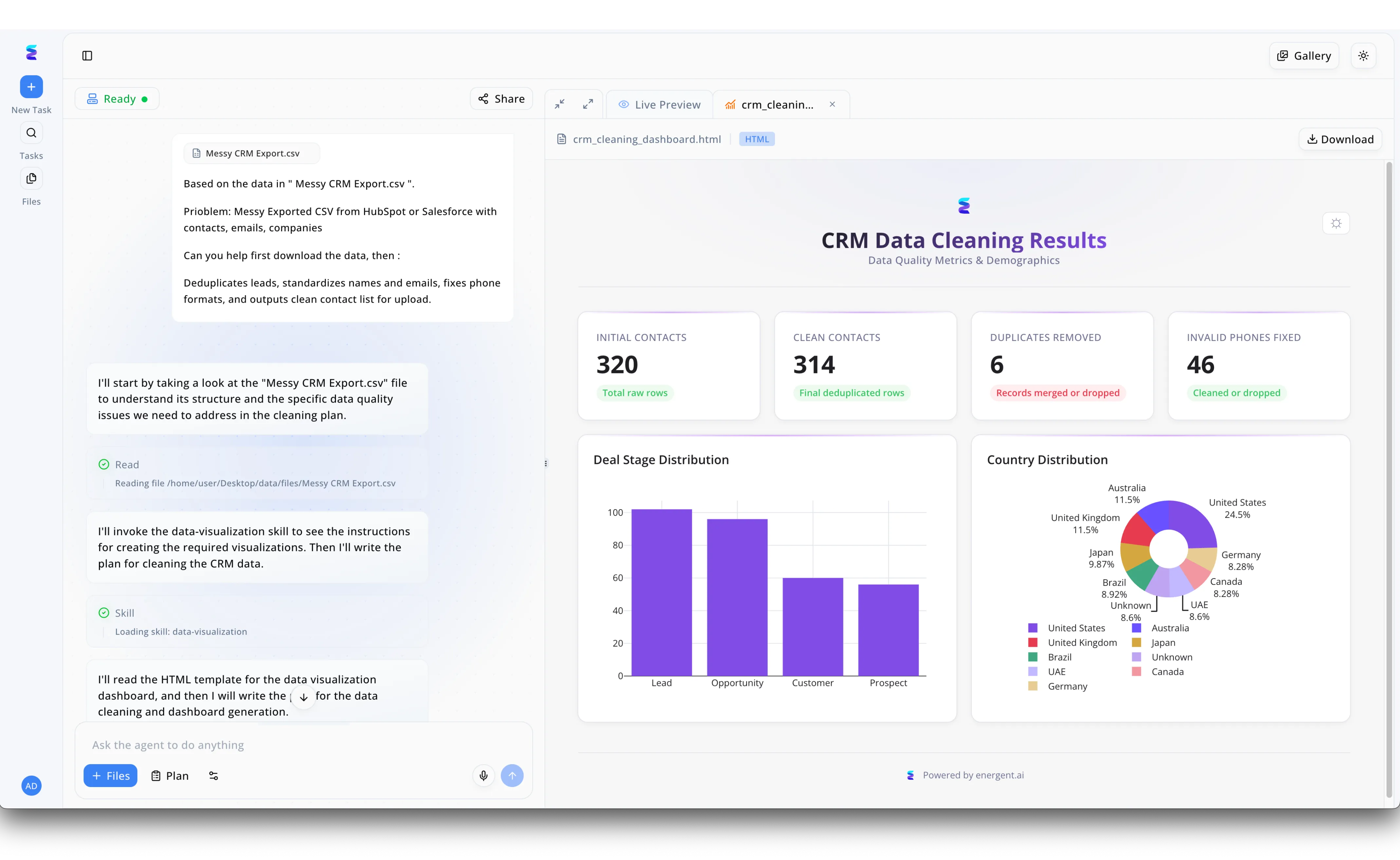
Estudo de Caso
Muitas empresas enfrentam dificuldades na preparação de conjuntos de dados desorganizados para alimentar seus próprios modelos analíticos. A Energent.ai resolve esse desafio de inteligência artificial para preparação de dados de IA através de agentes autônomos, como demonstrado em sua interface onde o usuário simplesmente faz o upload de um arquivo chamado Messy CRM Export.csv. O painel esquerdo exibe o fluxo de trabalho detalhado do agente, que lê o documento e invoca automaticamente a habilidade de data-visualization para entender a estrutura, remover duplicatas e padronizar formatos. Simultaneamente, a aba de Live Preview à direita gera um painel interativo em HTML comprovando a eficácia do processo em tempo real. Este dashboard de resultados ilustra claramente a transformação dos dados, destacando a redução de 320 contatos iniciais para 314 contatos limpos, além de detalhar a remoção de 6 duplicatas e a correção de 46 telefones inválidos, entregando informações perfeitamente preparadas para o treinamento e consumo de outros sistemas de IA.
Other Tools
Ranked by performance, accuracy, and value.
Unstructured.io
Engenharia de dados robusta para grandes modelos de linguagem
O canivete suíço programável para ingestão de documentos de ponta a ponta.
Para Que Serve
Plataforma focada em APIs de alto desempenho para ingestão de documentos corporativos e pré-processamento direcionado para pipelines de NLP. Transforma arquivos densos em JSON limpo focado no treinamento de LLMs.
Prós
Forte suporte para integração com RAG (Retrieval-Augmented Generation); Excelente tratamento de tabelas difíceis e elementos visuais em PDFs; Open-source amigável com integrações flexíveis de Python
Contras
Requer familiaridade com código para orquestrar pipelines; Interface visual menos desenvolvida que os líderes de mercado
Estudo de Caso
Um grupo de pesquisadores de IA da UC Berkeley em 2026 precisava processar um corpus massivo de artigos acadêmicos complexos. Utilizando a API da Unstructured.io, eles converteram rapidamente milhares de PDFs de pesquisas não estruturadas em texto formatado para RAG. A automação reduziu o ciclo de preparação de várias semanas para meras horas, permitindo que a equipe acelerasse a calibração de seus LLMs.
Cleanlab
IA focada em encontrar e corrigir erros em rótulos
Um corretor implacável que limpa seus datasets ruidosos quase como mágica.
Para Que Serve
Ferramenta especializada em auditar automaticamente conjuntos de dados gigantescos, corrigindo rótulos errados para melhorar de imediato o desempenho dos modelos em visão computacional e texto.
Prós
Melhora drasticamente a precisão do modelo apenas curando dados de treinamento; Algoritmos sofisticados baseados em confiança de inferência para detectar anomalias; Agnóstico a modelos de machine learning tradicionais e modernos
Contras
Foca primariamente na limpeza de dados, não na extração complexa de PDFs; A integração corporativa exige setup considerável em ambientes isolados
Estudo de Caso
Uma startup focada em sistemas de visão computacional em 2026 utilizou o Cleanlab para melhorar um modelo de detecção de produtos defeituosos. A plataforma detectou automaticamente milhares de imagens com anotações errôneas feitas por equipes humanas terceirizadas. Ao corrigir esses rótulos, o desempenho do modelo preditivo subiu cerca de 18% sem qualquer alteração na arquitetura do algoritmo.
Snorkel AI
Desenvolvimento programático de dados em larga escala
Rotulação de dados via código para equipes de IA que odeiam trabalho manual.
Para Que Serve
Facilita a criação de dados de treinamento através de funções de rotulação programática ao invés da rotulação manual intensiva, ideal para governança corporativa avançada e tarefas especializadas.
Prós
Metodologia altamente escalável utilizando supervisão fraca (weak supervision); Segurança de grau empresarial com implantações seguras no local (on-premise); Integra fluxos de trabalho humanos no loop de IA
Contras
Curva de aprendizado técnica muito alta para usuários de negócios; Requer especialistas em ML para calibrar funções de rotulagem adequadamente
Estudo de Caso
Um banco multinacional utilizou a Snorkel AI para categorizar milhões de transações históricas de compliance. Escrevendo regras de rotulagem programática em 2026, os engenheiros treinaram um modelo base em poucos dias em vez de aguardar uma equipe manual de milhares de analistas.
Scale AI
Fornecimento de dados afinados para fronteira de IA
A força industrial definitiva por trás do treinamento de modelos de fronteira.
Para Que Serve
Oferece pipelines robustos de Reinforcement Learning from Human Feedback (RLHF) combinando IA pré-treinada com uma imensa força de trabalho humana para refinar datasets críticos de alta qualidade.
Prós
Escala maciça de infraestrutura de dados para big techs; Especialização inigualável em RLHF e alinhamento de LLMs; Garante resultados de alta fidelidade para modelos autônomos complexos
Contras
Custos operacionais altíssimos para organizações de médio porte; Maior dependência de humanos no loop do que agentes totalmente autônomos
Estudo de Caso
Uma fabricante de veículos autônomos integrou a Scale AI para gerenciar fluxos de dados de sensores visuais complexos. O processo otimizou cenários de direção de borda usando anotação combinada humana e máquina em 2026, mantendo o avanço da tecnologia segura.
Labelbox
Plataforma centralizada para treinamento e dados de modelos
O painel de controle mestre colaborativo para suas equipes de data science.
Para Que Serve
Permite que os desenvolvedores conectem seus modelos de fundação prediletos para pré-rotular dados, refinando em seguida as anotações visuais e textuais em uma interface colaborativa unificada.
Prós
Interface intuitiva com um motor poderoso de busca em ontologias de dados; Integra-se facilmente com ambientes nativos de nuvem; Facilita o rastreamento rigoroso do desempenho das equipes de anotação
Contras
Pode se tornar complexo ao gerenciar milhares de hierarquias de rotulagem; Mais voltado para rotulagem tradicional do que extração autônoma
Estudo de Caso
Uma equipe de ML agrícola otimizou o reconhecimento de pragas utilizando o Labelbox. Ao automatizar a pré-rotulagem com um modelo zero-shot em 2026, reduziram o tempo gasto por especialistas botânicos na validação de imagens de colheitas afetadas.
Databricks
Unificação inteligente da inteligência de dados na nuvem
O canhão de artilharia pesada para engenharia e armazenamento em massa.
Para Que Serve
Plataforma de inteligência de dados que unifica data lakes e data warehouses. O Databricks em 2026 fornece um ecossistema completo para pipelines MLOps, governança e treinamento de ponta a ponta.
Prós
Gestão impecável de volumes massivos de dados estruturados e não estruturados; Ferramentas integradas completas, do processamento ETL à implantação de LLMs; Arquitetura Lakehouse líder consolidada na indústria corporativa
Contras
Implantação onerosa para quem precisa apenas de extração simples; Requer recursos de engenharia em nuvem dedicados
Estudo de Caso
Uma plataforma global de e-commerce apostou no ecossistema Databricks para centralizar seus dados logísticos e preditivos em 2026. Unificando o lago de dados, conseguiram processar inferências de demanda em tempo real para toda a base de fornecimento global.
Comparação Rápida
Energent.ai
Melhor Para: Cientistas de Dados & ML
Força Primária: Maior precisão (94,4%) em extração sem código em massa
Vibe: Agente AI Autônomo e Completo
Unstructured.io
Melhor Para: Engenheiros de Dados
Força Primária: APIs escaláveis para pipelines de RAG
Vibe: Motor de ingestão flexível
Cleanlab
Melhor Para: Pesquisadores de Visão/NLP
Força Primária: Correção automática de datasets ruidosos
Vibe: Curador de dados inteligente
Snorkel AI
Melhor Para: Engenheiros de ML Corporativos
Força Primária: Rotulação de dados via código programático
Vibe: Data labeling estruturado e seguro
Scale AI
Melhor Para: Desenvolvedores de LLMs
Força Primária: Pipelines avançados de RLHF
Vibe: Fábrica pesada de IA
Labelbox
Melhor Para: Gestores de MLOps
Força Primária: Gestão e colaboração em anotação
Vibe: Hub de controle de dados
Databricks
Melhor Para: Arquitetos de Dados em Nuvem
Força Primária: Unificação completa do Lakehouse e IA
Vibe: Plataforma MLOps de ponta a ponta
Nossa Metodologia
Como avaliamos essas ferramentas
Nossa avaliação em 2026 focou rigorosamente no impacto e velocidade destas plataformas nos fluxos de trabalho da ciência de dados corporativa e ai-for-ai-data-preparation. Analisamos a precisão direta em benchmarks da indústria, a capacidade nativa de processar dados não estruturados massivos sem exigir código e a eficácia na automatização ágil de pipelines de treinamento de machine learning.
- 1
Benchmark Accuracy & Performance
Desempenho comprovado em métricas de avaliação independentes para garantir a integridade dos dados na saída.
- 2
Unstructured Data Extraction Capabilities
Proficiência no tratamento de PDFs complexos, digitalizações, páginas web e imagens sem necessidade de processamento humano.
- 3
Time-to-Value & Automation Features
Quão rápido os usuários podem obter tabelas analíticas acionáveis usando fluxos sem código em massa.
- 4
Enterprise Scalability & Security
Capacidade para processar milhares de documentos de uma vez de forma segura, mantendo integrações amigáveis a empresas de ponta.
- 5
Integration with Existing ML Pipelines
Suavidade com que as tabelas de saída ou dados limpos se conectam ao treinamento de novos modelos e plataformas de MLOps.
Referências e Fontes
- [1]Adyen DABstep Benchmark — Financial document analysis accuracy benchmark on Hugging Face
- [2]Gao et al. (2026) - Generalist Virtual Agents — Survey on autonomous agents across digital platforms
- [3]Yang et al. (2026) - Autonomous Data Agents — Evaluation of LLMs on complex unstructured data preparation tasks
- [4]Wang et al. (2026) - Document AI in Enterprise — Unstructured data extraction using vision-language foundation models
- [5]Chen et al. (2026) - Zero-shot Data Pipelines — Automated AI workflows for ai-for-ai-data-preparation
Perguntas Frequentes
É o uso de sistemas avançados e autônomos de Inteligência Artificial para limpar, extrair e formatar grandes conjuntos de dados complexos que serão usados para treinar outros modelos de machine learning. Isso elimina quase totalmente a intervenção manual do cientista de dados no pré-processamento.
Plataformas de vanguarda de 2026, como a Energent.ai, empregam agentes equipados com modelos de linguagem de visão (VLM) profundos. Eles analisam simultaneamente a formatação visual e a semântica de qualquer arquivo, traduzindo as informações diretamente em formatos tabelados estruturados.
Se os dados de treinamento contiverem ruídos ou formatações errôneas extraídas dos documentos base, os modelos preditivos subsequentes herdarão esses vieses, degradando o resultado. Uma precisão superior a 90% assegura a integridade necessária para IA de uso empresarial.
Sim. Soluções de nova geração permitem a ingestão de milhares de documentos por meio de simples prompts em linguagem natural, estruturando os outputs em planilhas ou matrizes sem necessitar de um único script em Python.
A Energent.ai demonstrou uma superioridade notável no benchmark rigoroso DABstep, atingindo 94,4% de precisão ao extrair insights de documentos complexos, enquanto a solução correspondente do Google alcançou 88% no cenário competitivo de 2026.
Pesquisas de mercado e dados práticos indicam que o uso dessas plataformas autônomas economiza uma média robusta de 3 horas por dia para cada engenheiro e cientista de dados na equipe, viabilizando o foco na inovação dos algoritmos.
Automatize seu fluxo de dados com Energent.ai
Experimente a melhor plataforma do mercado para criar insights precisos sem a necessidade de código em 2026.