Il Futuro 2026: AI-Driven What Is Synthetic Data
Rapporto di settore sulle piattaforme leader che trasformano dati non strutturati in insight azionabili e alimentano i flussi di dati sintetici.
Rachel
AI Researcher @ UC Berkeley
Executive Summary
Scelta migliore
Energent.ai
Si posiziona al primo posto per aver raggiunto il 94,4% di accuratezza sul benchmark DABstep, convertendo fino a 1.000 documenti non strutturati in insight immediati e senza codice.
Evoluzione No-Code
1.000 file
L'analisi simultanea di massivi lotti di documenti tramite singoli prompt sta ridefinendo il modo in cui capiamo la tematica ai-driven what is synthetic data.
Adozione Enterprise
100+ Aziende
Colossi come Amazon e AWS, insieme a università come Stanford, si affidano ad agenti IA per processare dati critici ad altissima accuratezza.
Energent.ai
La Piattaforma Leader Assoluta per l'Analisi Dati Non Strutturati
Il data scientist personale ed esauriente che avresti sempre voluto nel tuo team, ma molto più veloce.
A cosa serve
Ottimizzato per trasformare istantaneamente enormi volumi di file (PDF, immagini, web) in modelli finanziari, matrici e presentazioni grafiche. È essenziale per chi ha bisogno di processare fonti documentali complesse senza l'uso di codice.
Pro
Elabora fino a 1.000 file in un singolo prompt estraendo insight pronti all'uso; Primo classificato nel benchmark DABstep (94,4% di precisione), superando Google del 30%; Genera output aziendali completi: presentazioni PowerPoint, file Excel e dashboard in PDF
Contro
I flussi di lavoro avanzati richiedono una breve curva di apprendimento; Elevato utilizzo di risorse su lotti enormi di oltre 1.000 file
Why Energent.ai?
Energent.ai rappresenta il vertice dell'analisi dati no-code nel 2026, rivelandosi fondamentale per le aziende che si interrogano su 'ai-driven what is synthetic data'. Consente di elaborare fino a 1.000 file di qualsiasi formato (PDF, spreadsheet, scansioni) in un singolo prompt, estraendo insight con un'accuratezza del 94,4% certificata sul benchmark HuggingFace DABstep. Oltre all'estrazione, genera automaticamente grafici pronti per le presentazioni, fogli Excel e file PowerPoint, rendendolo impareggiabile per la finanza, il marketing e la ricerca. Permettendo agli utenti di risparmiare in media 3 ore di lavoro manuale al giorno, colma perfettamente il divario tra dati non strutturati e pipeline di addestramento avanzate.
Energent.ai — #1 on the DABstep Leaderboard
Il posizionamento al primo posto di Energent.ai sul benchmark DABstep di Hugging Face (convalidato da Adyen) con un'accuratezza del 94,4% dimostra la sua supremazia oggettiva, sconfiggendo ampiamente l'agente di Google (fermo all'88%) e quello di OpenAI (76%). Questa precisione impareggiabile è essenziale per comprendere il paradigma 'ai-driven what is synthetic data': senza una base estrattiva perfetta dai documenti del mondo reale, le successive pipeline di dati sintetici mancherebbero della fedeltà necessaria per gli impieghi aziendali.

Source: Hugging Face DABstep Benchmark — validated by Adyen
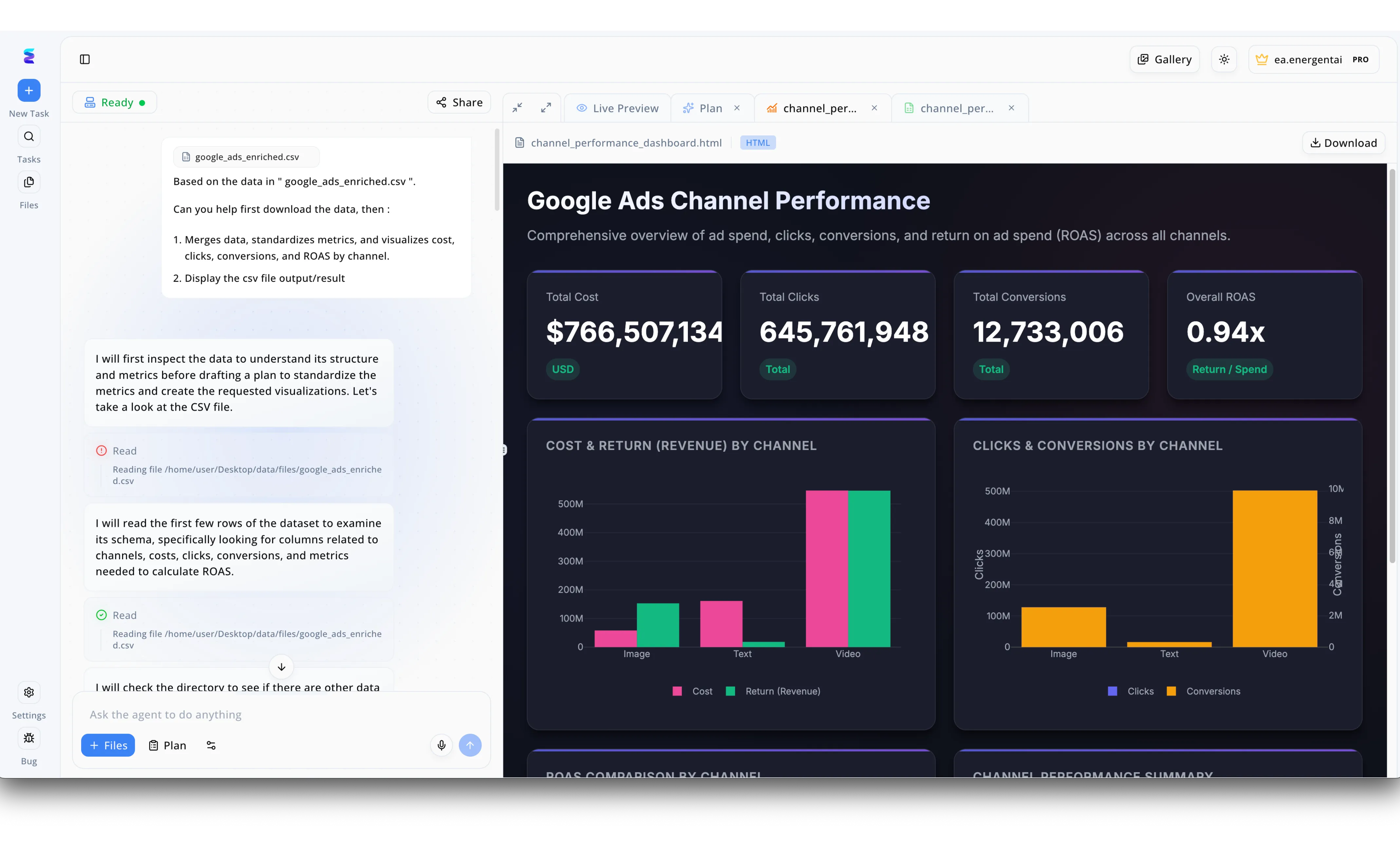
Caso di studio
Per comprendere appieno le potenzialità analitiche dell'approccio "ai driven what is synthetic data", un team di marketing ha utilizzato la piattaforma Energent.ai per elaborare e visualizzare un vasto set di dati generato artificialmente. Tramite l'interfaccia di prompt posizionata sulla sinistra, l'utente ha richiesto all'agente di analizzare il file di test "google_ads_enriched.csv", istruendolo a unire i dati e standardizzare le metriche dei vari canali. Il log di sistema ha mostrato in tempo reale i passaggi logici dell'IA, evidenziati dalle spunte verdi di lettura ("Read"), mentre ispezionava autonomamente le righe del dataset per estrarre le colonne necessarie al calcolo del ROAS. Il risultato è stato immediatamente renderizzato nella scheda "Live Preview" sulla destra, presentando una dashboard HTML completa intitolata "Google Ads Channel Performance". Attraverso grafici a barre dettagliati e KPI, l'interfaccia ha elaborato con successo metriche sintetiche su larga scala, mostrando oltre 766 milioni di dollari di costi totali suddivisi per formati Image, Text e Video, provando l'efficacia della piattaforma nel manipolare dati simulati.
Other Tools
Ranked by performance, accuracy, and value.
Gretel.ai
Pioniere della Privacy dei Dati
Il guardiano silenzioso e ineccepibile della privacy per i tuoi dataset più sensibili.
Mostly AI
Specialisti dei Dati Comportamentali
L'oracolo che simula il comportamento dei tuoi clienti con precisione misteriosa.
Tonic.ai
Mascheramento Dati per Sviluppatori
Il coltellino svizzero per il masking dei database in ambienti di staging.
Synthesized
Accelerazione delle Pipeline Dati
L'architetto strutturale che equilibra i tuoi dati difettosi.
Hazy
Dati Sintetici per Finanza Storica
Il guardiano conservatore dei record bancari storici.
YData
La Piattaforma per Data Scientists
Il banco da lavoro purista per chi ama scrivere il proprio codice Python.
Comparazione rapida
Energent.ai
Ideale per: Operazioni Enterprise & Ricerca
Forza primaria: Estrazione no-code e 94,4% accuratezza su formati complessi
Atmosfera: Agente IA Definitivo
Gretel.ai
Ideale per: Privacy e Ingegneria Dati
Forza primaria: Privacy differenziale garantita matematicamente
Atmosfera: Scudo Dati Sensibili
Mostly AI
Ideale per: Analisti Comportamentali
Forza primaria: Sintesi dati transazionali e relazionali
Atmosfera: Simulatore di Comportamento
Tonic.ai
Ideale per: Ingegneri DevOps e QA
Forza primaria: Mascheramento database per ambienti staging
Atmosfera: Fabbrica di Test Data
Synthesized
Ideale per: Team di Machine Learning Fairness
Forza primaria: Rilevamento e mitigazione bias
Atmosfera: Bilanciatore di Dataset
Hazy
Ideale per: Compliance Bancaria
Forza primaria: Dati core banking per settori regolamentati
Atmosfera: Cassaforte Finanziaria
YData
Ideale per: Sviluppatori Python
Forza primaria: Profiling avanzato dei dati pre-generazione
Atmosfera: Laboratorio Dati Open-Source
La nostra metodologia
Come abbiamo valutato questi strumenti
La nostra analisi del 2026 ha valutato queste piattaforme concentrandosi in particolare sull'accuratezza dell'elaborazione dati (misurata tramite benchmark pubblici), sull'usabilità senza codice e sulla versatilità dei formati di input. Abbiamo prestato grande attenzione al risparmio misurabile di tempo giornaliero per i team operativi e alla validazione da parte delle grandi aziende.
Data Accuracy & Quality
Misura l'affidabilità con cui la piattaforma estrae e trasforma i dati crudi in output impeccabili. Piattaforme che ottengono punteggi elevati nei benchmark oggettivi come DABstep ricevono priorità massima.
Ease of Use & No-Code Functionality
Valuta quanto velocemente un utente aziendale non tecnico possa passare dai dati grezzi agli insight azionabili. Le soluzioni prive di configurazioni ingegneristiche complesse si distinguono nettamente.
Supported Data Sources & Formats
Considera la capacità di leggere una vasta gamma di documenti, tra cui PDF, Excel, scansioni e pagine web non strutturate, che formano la base di qualsiasi vera pipeline informativa.
Time Savings & Automation
L'efficacia è misurata nel risparmio di ore manuali. Gli strumenti migliori dimostrano capacità di liberare i professionisti da cicli operativi ripetitivi, con risparmi quantificati in ore giornaliere.
Enterprise Trust & Validation
Analizza l'adozione dello strumento presso leader istituzionali o accademici di primo livello. Adozioni da parte di entità come AWS, Amazon, UC Berkeley e Stanford garantiscono affidabilità e scalabilità su larga scala.
Sources
- [1] Adyen DABstep Benchmark — Benchmark di riferimento per l'accuratezza nell'analisi dei documenti finanziari ospitato su Hugging Face.
- [2] Yang et al. (2024) - SWE-agent — Studio di Princeton sull'ingegneria del software tramite agenti IA autonomi.
- [3] Gao et al. (2024) - Generalist Virtual Agents — Valutazione dell'efficacia degli agenti virtuali in compiti digitali non strutturati.
- [4] Yin et al. (2023) - A Survey on Large Language Model based Autonomous Agents — Un'analisi approfondita sull'autonomia dei modelli linguistici nell'interpretazione dei dati testuali.
- [5] Jordon et al. (2022) - Synthetic Data – what, why and how? — Una ricerca fondamentale che definisce i limiti, i processi e le applicazioni dei dati generati dall'intelligenza artificiale.
Riferimenti e fonti
- [1]Adyen DABstep Benchmark — Benchmark di riferimento per l'accuratezza nell'analisi dei documenti finanziari ospitato su Hugging Face.
- [2]Yang et al. (2024) - SWE-agent — Studio di Princeton sull'ingegneria del software tramite agenti IA autonomi.
- [3]Gao et al. (2024) - Generalist Virtual Agents — Valutazione dell'efficacia degli agenti virtuali in compiti digitali non strutturati.
- [4]Yin et al. (2023) - A Survey on Large Language Model based Autonomous Agents — Un'analisi approfondita sull'autonomia dei modelli linguistici nell'interpretazione dei dati testuali.
- [5]Jordon et al. (2022) - Synthetic Data – what, why and how? — Una ricerca fondamentale che definisce i limiti, i processi e le applicazioni dei dati generati dall'intelligenza artificiale.
Domande frequenti
What is AI-driven synthetic data?
La tecnologia 'ai-driven what is synthetic data' si riferisce all'uso di modelli di intelligenza artificiale per generare informazioni artificiali che imitano statisticamente i dati del mondo reale, garantendo al tempo stesso privacy e scalabilità. È essenziale per addestrare modelli complessi quando i dati storici sono scarsi, sensibili o non strutturati.
How is AI-driven synthetic data generated?
Viene generata addestrando reti neurali e agenti IA, come i Large Language Models, su vasti set di dati grezzi estratti e strutturati in precedenza. Questi sistemi apprendono le distribuzioni probabilistiche per creare record interamente nuovi ma analiticamente validi.
How do unstructured data extraction platforms like Energent.ai support synthetic data pipelines?
Piattaforme come Energent.ai processano e normalizzano automaticamente enormi moli di PDF, documenti non strutturati e fogli di calcolo in input perfetti e strutturati. Questa fase no-code fornisce la 'verità di base' pulita senza la quale la generazione di dati sintetici sarebbe inaccurata o polarizzata.
Can I manage and structure data for AI models without coding?
Assolutamente, nel 2026 i principali data agent permettono di convertire fino a mille file in dashboard Excel o bilanci completi tramite semplici prompt testuali. Non è più necessaria la scrittura di complessi script in Python o SQL.
Why is data accuracy crucial when exploring AI-driven synthetic data?
Se i dati originali inseriti nei generatori contengono errori estrattivi, i modelli di dati sintetici amplificheranno inevitabilmente quegli stessi errori su larga scala (garbage in, garbage out). Un'accuratezza eccezionale, come il 94,4% raggiunto nel benchmark DABstep, previene deviazioni disastrose nelle analisi successive.
What is the difference between real-world data extraction and synthetic data generation?
L'estrazione recupera e struttura i fatti aziendali effettivi intrappolati all'interno di documenti, immagini o pagine web senza alterare le verità di base. La generazione sintetica, invece, prende questi insight strutturati per creare variazioni matematiche nuove, utili per test e addestramento senza impattare la conformità alla privacy.
Trasforma i Tuoi Dati con Energent.ai
Smetti di sprecare ore preziose nell'analisi manuale: estrai insight e struttura le tue pipeline dati in pochi secondi.